Una red neuronal artificial es un sistema informático compuesto por unidades de procesamiento matemático (neuronas artificiales) organizadas en capas interconectadas. Inspirada en el funcionamiento del cerebro humano, aprende a partir de datos ajustando sus "pesos sinápticos" para realizar tareas como el reconocimiento de imágenes o el procesamiento del lenguaje, sin programación explícita de todas las reglas.
Para abordar el funcionamiento de las redes neuronales artificiales, es necesario comprender el significado de la inteligencia artificial (IA). La IA consiste en crear sistemas informáticos capaces de automatizar tareas sin intervención humana, así como de aprender, adaptarse, mejorar, comunicarse y, sobre todo, tomar decisiones. En este sentido, la IA busca reproducir aspectos de la inteligencia humana.
La definición de inteligencia es muy debatible, pero el sentido que nos interesa aquí es el de funciones controladas por el cerebro. De hecho, ya sean mecánicas como caminar o cognitivas como la toma de decisiones, la arquitectura de las funciones sigue siendo la misma en todas las áreas cerebrales de nuestro cerebro. Además, todas las funciones son de igual importancia, sin distinción entre las consideradas nobles o menos nobles. Todas se realizan con la misma complejidad de cálculos, a través de una enorme red de miles de millones de neuronas interconectadas entre sí para intercambiar información. La información se intercambia mediante señales eléctricas y químicas.
En el cerebro humano, el proceso de comunicación entre neuronas es el siguiente:
- Cuando las señales eléctricas, iniciadas a nivel de la membrana celular de la neurona, alcanzan un umbral crítico, desencadenan un breve impulso eléctrico llamado "potencial de acción". Los potenciales de acción viajan a lo largo del axón hasta la sinapsis de la neurona.
- A nivel de la sinapsis (puntos de contacto entre neuronas), los potenciales de acción desencadenan la liberación de moléculas químicas llamadas "neurotransmisores".
- Los neurotransmisores se unen luego a los receptores ubicados en la membrana de la neurona postsináptica (la neurona receptora). Esta unión química desencadena una respuesta eléctrica en la neurona postsináptica.
- La neurona postsináptica integra todas las entradas que recibe de las neuronas emisoras, y si se alcanza el umbral crítico, genera a su vez un potencial de acción que se propaga a lo largo de su propio axón, continuando así la transmisión de información en la red.
Según los tipos de neurotransmisores liberados, la actividad presináptica puede tener un efecto excitador o inhibitorio sobre la actividad eléctrica de la neurona postsináptica. Esto hace que el desencadenamiento de un potencial de acción sea más o menos probable.
Este proceso complejo es la base del funcionamiento del cerebro y la cognición humana. A partir de este proceso, los investigadores elaboraron un modelo de inteligencia artificial, muy simple al principio y cada vez más sofisticado a medida que avanza la tecnología.
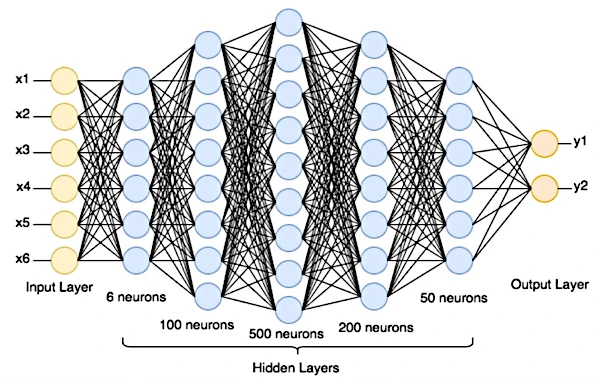
La neurona artificial es la unidad básica de una red neuronal artificial. Una red neuronal artificial está compuesta por una sucesión de capas de neuronas interconectadas, donde cada capa toma sus entradas de las salidas de la capa anterior.
Las neuronas artificiales no son bits informáticos (0 o 1), sino más bien abstracciones matemáticas (números, operaciones, funciones, ecuaciones, matrices, conjuntos, probabilidades, etc.). En otras palabras, son unidades de procesamiento que realizan operaciones matemáticas sobre los datos que se les presentan. No almacenan datos, a diferencia de los bits informáticos, que son la base del almacenamiento de información digital.
En una red neuronal artificial, cada neurona se caracteriza por un nivel de actividad capturado por una variable llamada "potencial de activación". La sinapsis de la neurona se caracteriza por otra variable llamada "peso sináptico".
- El potencial de activación representa el estado eléctrico de la neurona postsináptica en un momento dado. Se calcula sumando las señales de entrada provenientes de las neuronas presinápticas, donde cada señal está modulada por el peso sináptico correspondiente. El potencial de activación puede variar de manera continua en un rango que va desde valores negativos hasta positivos, dependiendo de la intensidad de las señales entrantes.
- Los pesos sinápticos determinan si una conexión sináptica es excitadora, inhibidora o nula. Los pesos modulan el impacto de las señales de entrada en el potencial de activación. Los pesos positivos aumentan la actividad, los pesos negativos la reducen y los pesos nulos no tienen efecto.
El potencial de activación resulta de la combinación de las señales de entrada ponderadas por los pesos sinápticos. Este potencial luego se somete a una función de activación, que introduce una no linealidad y determina si la neurona postsináptica genera una respuesta (potencial de acción) o no. En definitiva, estos mecanismos permiten a la neurona procesar información y responder de manera adaptativa a los estímulos. El funcionamiento de estas variables es fundamental para modelar el comportamiento de las neuronas, tanto en redes neuronales biológicas como en redes neuronales artificiales.
Imaginemos una red neuronal artificial utilizada para la clasificación de imágenes. Esta red tiene una neurona postsináptica que recibe conexiones de tres neuronas presinápticas. Cada una de estas tres neuronas presinápticas está asociada con una característica específica de la imagen que la red analiza, como la presencia de líneas verticales, líneas horizontales y curvas.
La neurona postsináptica tiene un potencial de activación inicial de 0.
Cuando las tres neuronas presinápticas envían sus señales, cada señal se multiplica por el peso sináptico asociado con la conexión correspondiente. Supongamos que los pesos sinápticos son los siguientes:
- Peso sináptico para la característica de líneas verticales: +0.5
- Peso sináptico para la característica de líneas horizontales: -0.3
- Peso sináptico para la característica de curvas: +0.2
Las señales de las tres neuronas presinápticas se ponderan por sus respectivos pesos sinápticos y se suman.
Si tenemos las siguientes señales:
- Señal para líneas verticales: 1
- Señal para líneas horizontales: 0.5
- Señal para curvas: 0.8
El potencial de activación se calcularía de la siguiente manera:
Potencial de activación = (1 * 0.5) + (0.5 * (-0.3)) + (0.8 * 0.2) = 0.5 - 0.15 + 0.16 = 0.51
Si el potencial de activación supera un umbral definido (por ejemplo, 0), la neurona postsináptica generará un potencial de acción, indicando que la característica buscada ha sido detectada en la imagen.
En este ejemplo, los pesos sinápticos desempeñan un papel crucial al determinar la importancia relativa de cada característica de la imagen. Las señales de entrada ponderadas por los pesos sinápticos se utilizan para calcular el potencial de activación, que, si supera el umbral, desencadenará la respuesta de la neurona postsináptica. Esto permite a la red neuronal tomar decisiones basadas en las características detectadas en la imagen.
La infraestructura de hardware de una red neuronal artificial no tiene nada de biológico; es la misma que la de la informática clásica (microprocesadores, tarjetas gráficas, etc.).
La infraestructura de software de una red neuronal artificial es diferente. Los algoritmos de aprendizaje automático (machine learning) aprenden a partir de datos y ajustan su comportamiento en función de los ejemplos proporcionados, mientras que los algoritmos de programación tradicional se basan en instrucciones explícitas estáticas que no cambian por sí mismas. En este sentido, la IA es una revolución, porque para escribir de manera estática las reglas de ChatGPT 3.5 con sus 175 mil millones de parámetros, habría llevado miles de años.
Una red neuronal está organizada en capas donde cada neurona artificial (función matemática) recibe entradas, realiza cálculos sobre estas entradas y genera una salida. La primera capa es la capa de entrada, que recibe los datos en bruto (texto, imagen digital u otros datos recolectados). Detrás, hay una o varias capas ocultas (no accesibles desde el exterior), seguidas de la capa de salida que produce las predicciones.
Para realizar una predicción, los datos se propagan desde la capa de entrada hasta la capa de salida. Cada neurona suma sus entradas ponderadas, aplica una función de activación y pasa el resultado a la siguiente capa.
Las funciones de activación introducen no linealidades en la red. Esto significa que la relación entre las cantidades no es una proporción constante, sino una probabilidad. Esto es lo que confiere a las redes neuronales su capacidad para resolver una variedad de problemas, desde el reconocimiento de imágenes hasta la traducción automática, pasando por el modelado del lenguaje natural.
Después de realizar una predicción, la red compara sus propios resultados con las etiquetas correctas para medir el error o la diferencia entre ambos. Las etiquetas correctas son un componente esencial del conjunto de entrenamiento de un modelo de aprendizaje supervisado. Se proporcionan para cada ejemplo del conjunto de entrenamiento para permitir que el modelo aprenda a hacer predicciones precisas.
En el siguiente paso, el algoritmo de retropropagación ajusta los pesos de la red (parámetros internos que determinan cómo las neuronas responden a las entradas). Esto le permite encontrar los valores que minimizan el error del modelo. Este proceso se repite hasta que la red alcance un nivel de rendimiento satisfactorio.
En la red, también existen hiperparámetros que ajustar, como la tasa de aprendizaje, el tamaño del lote utilizado, la arquitectura de la red, la elección de la función de activación en las capas, etc.
Después de evaluar el modelo para cada combinación, los investigadores eligen los hiperparámetros que ofrecen el mejor rendimiento en los datos de validación.
Al final, el modelo entrenado se evalúa con nuevos datos nunca antes vistos.
Supongamos que tenemos a disposición un centro de datos capaz de proporcionarnos 100,000 imágenes diferentes de 28x28 píxeles en escala de grises que representan dígitos manuscritos del 0 al 9.
Nuestra red neuronal tendrá una capa de entrada configurada al tamaño de las imágenes (28x28 neuronas), una o varias capas ocultas y una capa de salida con 10 neuronas (ya que hay 10 dígitos posibles: 0 al 9). Cada neurona en la capa de salida representa la probabilidad de que la imagen corresponda a un dígito en particular.
Los pesos de las conexiones entre las neuronas se definen inicialmente con valores aleatorios.
Los datos en bruto, por ejemplo, la imagen digital del número 3, se introducen en la capa de entrada.
Para analizar las regiones locales de la imagen, los filtros de convolución se deslizan sobre la imagen para extraer un mapa de características visuales jerárquicas. Las primeras capas detectan bordes, mientras que las capas superiores detectan patrones más complejos.
Los datos se propagan a través de la red siguiendo las conexiones ponderadas y aplicando funciones de activación. En cada capa, se realizan operaciones matemáticas para obtener una salida.
La capa de salida produce puntuaciones para cada dígito (0-9). Una función transforma estas puntuaciones en probabilidades. El dígito con la probabilidad más alta será la predicción de la red.
A continuación, la red comparará su predicción con la etiqueta real de la imagen.
Una función de costo mide la divergencia entre las predicciones del modelo y las etiquetas reales.
Para ello, el error se propaga en sentido inverso a través de la red. La red ajusta sus parámetros (pesos y sesgos) en cada capa para minimizar el error, mediante algoritmos como el descenso de gradiente.
Este proceso se repite sobre un número muy grande de imágenes de entrenamiento. La red ajustará sus parámetros en cada iteración para mejorar en la clasificación de dígitos manuscritos. Una vez que la red está entrenada, se prueba con un conjunto de datos distinto para evaluar su rendimiento.
Una red neuronal artificial se inspira en el funcionamiento del cerebro humano: neuronas interconectadas intercambian señales cuyo impacto está modulado por pesos sinápticos. En su versión artificial, cada neurona es una función matemática que calcula una suma ponderada de sus entradas, aplica una función de activación y transmite el resultado.
El aprendizaje consiste en ajustar automáticamente los pesos sinápticos a partir de ejemplos, mediante un proceso de retropropagación y optimización (descenso de gradiente). Es esta capacidad de aprender sin programación explícita de reglas lo que distingue a la IA de la informática tradicional.
En la práctica, la red está organizada en capas (entrada, ocultas, salida) y, tras un entrenamiento iterativo con datos etiquetados, se vuelve capaz de hacer predicciones sobre datos nuevos (reconocimiento de imágenes, procesamiento de lenguaje, etc.).
La neurona biológica intercambia información mediante señales eléctricas y químicas (neurotransmisores). La neurona artificial es una abstracción matemática (números, funciones) que realiza cálculos. No almacena datos, a diferencia de los bits informáticos, pero procesa la información mediante un potencial de activación y pesos sinápticos.
El aprendizaje se realiza en tres grandes etapas: primero, la red realiza una predicción propagando los datos de entrada a través de sus capas. Luego, compara su predicción con la etiqueta correcta mediante una función de costo. Finalmente, un algoritmo de retropropagación ajusta los pesos sinápticos para minimizar el error, repitiendo este proceso en muchos ejemplos.
Las funciones de activación introducen no linealidades en la red. Esto significa que la relación entre las cantidades no es una proporción constante, sino una probabilidad. Esta característica es lo que permite a las redes neuronales resolver problemas complejos como el reconocimiento de imágenes, la traducción automática o el modelado del lenguaje natural.
 Herramientas de IA: ¿cómo elegir?
Herramientas de IA: ¿cómo elegir? 
 IA Generativa vs AGI: ¿Dónde termina la imitación y dónde comienza la conciencia?
IA Generativa vs AGI: ¿Dónde termina la imitación y dónde comienza la conciencia?  Redes artificiales vs. redes biológicas: Dos sistemas, una arquitectura común
Redes artificiales vs. redes biológicas: Dos sistemas, una arquitectura común  Cerebro Humano e Inteligencias Artificiales: Similitudes y Diferencias
Cerebro Humano e Inteligencias Artificiales: Similitudes y Diferencias  AlphaGo contra AlphaGo Zero: Una Revolución en la Inteligencia Artificial
AlphaGo contra AlphaGo Zero: Una Revolución en la Inteligencia Artificial  El Próximo Paso para las Máquinas Inteligentes
El Próximo Paso para las Máquinas Inteligentes  El primer paso hacia el surgimiento de la vida
El primer paso hacia el surgimiento de la vida  De la Neurona Biológica a la Neurona Formal: Simplificación del Cerebro
De la Neurona Biológica a la Neurona Formal: Simplificación del Cerebro  Inteligencia artificial: la explosión del gigantismo
Inteligencia artificial: la explosión del gigantismo  ¡Cuando la inteligencia artificial se vuelve loca!
¡Cuando la inteligencia artificial se vuelve loca!  Emergencia de la inteligencia artificial: ¿Ilusión de inteligencia o inteligencia?
Emergencia de la inteligencia artificial: ¿Ilusión de inteligencia o inteligencia?  ¿Cómo las máquinas entienden, interpretan y generan el lenguaje de forma similar a los humanos?
¿Cómo las máquinas entienden, interpretan y generan el lenguaje de forma similar a los humanos?  ¿Cómo funciona una red neuronal artificial?
¿Cómo funciona una red neuronal artificial?