Uma rede neural artificial é um sistema computacional composto por unidades de processamento matemático (neurônios artificiais) organizadas em camadas interconectadas. Inspirada no funcionamento do cérebro humano, ela aprende a partir de dados ajustando seus "pesos sinápticos" para realizar tarefas como reconhecimento de imagens ou processamento de linguagem, sem programação explícita de todas as regras.
Para abordar o funcionamento das redes neurais artificiais, é necessário compreender o significado da inteligência artificial (IA). A IA consiste em criar sistemas computacionais capazes de automatizar tarefas sem intervenção humana, bem como aprender, adaptar-se, melhorar, comunicar e, acima de tudo, tomar decisões. Nesse sentido, a IA busca reproduzir aspectos da inteligência humana.
A definição de inteligência é muito discutível, mas o sentido que nos interessa aqui é o de funções controladas pelo cérebro. De fato, sejam mecânicas como caminhar ou cognitivas como a tomada de decisão, a arquitetura das funções permanece a mesma em todas as áreas cerebrais do nosso cérebro. Além disso, todas as funções são de igual importância, sem distinção entre aquelas consideradas nobres ou menos nobres. Todas são realizadas com a mesma complexidade de cálculos, por meio de uma enorme rede de bilhões de neurônios interconectados para trocar informações. A informação é trocada por meio de sinais elétricos e químicos.
No cérebro humano, o processo de comunicação entre neurônios é o seguinte:
- Quando os sinais elétricos, iniciados no nível da membrana celular do neurônio, atingem um limiar crítico, eles disparam um breve impulso elétrico chamado "potencial de ação". Os potenciais de ação viajam ao longo do axônio até a sinapse do neurônio.
- Na sinapse (pontos de contato entre os neurônios), os potenciais de ação disparam a liberação de moléculas químicas chamadas "neurotransmissores".
- Os neurotransmissores ligam-se, então, aos receptores localizados na membrana do neurônio pós-sináptico (o neurônio receptor). Essa ligação química dispara uma resposta elétrica no neurônio pós-sináptico.
- O neurônio pós-sináptico integra todas as entradas que recebe dos neurônios emissores, e se o limiar crítico for atingido, ele gera, por sua vez, um potencial de ação que se propaga ao longo de seu próprio axônio, continuando, assim, a transmissão da informação na rede.
Dependendo dos tipos de neurotransmissores liberados, a atividade pré-sináptica pode ter um efeito excitador ou inibidor sobre a atividade elétrica do neurônio pós-sináptico. Isso torna o disparo de um potencial de ação mais ou menos provável.
Esse processo complexo é a base do funcionamento do cérebro e da cognição humana. É a partir desse processo que os pesquisadores elaboraram um modelo de inteligência artificial, muito simples no início e cada vez mais sofisticado à medida que a tecnologia avança.
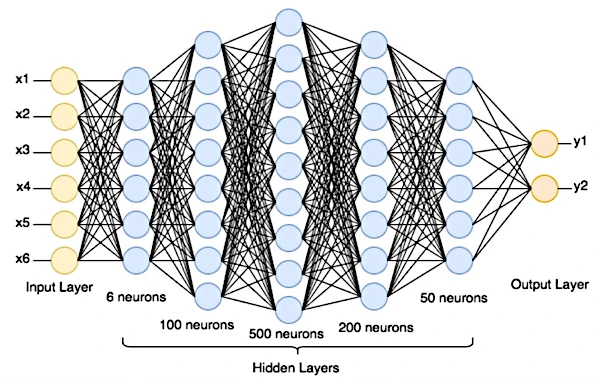
O neurônio artificial é a unidade básica de uma rede neural artificial. Uma rede neural artificial é composta por uma sucessão de camadas de neurônios interconectados, onde cada camada recebe suas entradas a partir das saídas da camada anterior.
Os neurônios artificiais não são bits computacionais (0 ou 1), mas sim abstrações matemáticas (números, operações, funções, equações, matrizes, conjuntos, probabilidades, etc.). Em outras palavras, são unidades de processamento que realizam operações matemáticas nos dados apresentados a elas. Eles não armazenam dados, ao contrário dos bits computacionais, que são a base do armazenamento de informações digitais.
Em uma rede neural artificial, cada neurônio é caracterizado por um nível de atividade capturado por uma variável chamada "potencial de ativação". A sinapse do neurônio é caracterizada por outra variável chamada "peso sináptico".
- O potencial de ativação representa o estado elétrico do neurônio pós-sináptico em um dado momento. Ele é calculado somando os sinais de entrada provenientes dos neurônios pré-sinápticos, sendo cada sinal modulado pelo peso sináptico correspondente. O potencial de ativação pode variar de forma contínua em uma faixa que vai de valores negativos a positivos, dependendo da intensidade dos sinais de entrada.
- Os pesos sinápticos determinam se uma conexão sináptica é excitatória, inibitória ou nula. Os pesos modulam o impacto dos sinais de entrada no potencial de ativação. Pesos positivos aumentam a atividade, pesos negativos a reduzem e pesos nulos não têm efeito.
O potencial de ativação resulta da combinação dos sinais de entrada ponderados pelos pesos sinápticos. Esse potencial é, então, submetido a uma função de ativação, que introduz uma não linearidade e determina se o neurônio pós-sináptico gera uma resposta (potencial de ação) ou não. No final das contas, esses mecanismos permitem que o neurônio processe informações e responda de forma adaptativa aos estímulos. O funcionamento dessas variáveis é fundamental para a modelagem do comportamento dos neurônios, tanto em redes neurais biológicas quanto em redes neurais artificiais.
Imaginemos uma rede neural artificial usada para classificação de imagens. Esta rede tem um neurônio pós-sináptico que recebe conexões de três neurônios pré-sinápticos. Cada um desses três neurônios pré-sinápticos está associado a uma característica específica da imagem que a rede está analisando, como a presença de linhas verticais, linhas horizontais e curvas.
O neurônio pós-sináptico tem um potencial de ativação inicial de 0.
Quando os três neurônios pré-sinápticos enviam seus sinais, cada sinal é multiplicado pelo peso sináptico associado à conexão correspondente. Suponhamos que os pesos sinápticos sejam os seguintes:
- Peso sináptico para a característica de linhas verticais: +0,5
- Peso sináptico para a característica de linhas horizontais: -0,3
- Peso sináptico para a característica de curvas: +0,2
Os sinais dos três neurônios pré-sinápticos são ponderados por seus respectivos pesos sinápticos e somados.
Se tivermos os seguintes sinais:
- Sinal para linhas verticais: 1
- Sinal para linhas horizontais: 0,5
- Sinal para curvas: 0,8
O potencial de ativação seria calculado da seguinte forma:
Potencial de ativação = (1 * 0,5) + (0,5 * (-0,3)) + (0,8 * 0,2) = 0,5 - 0,15 + 0,16 = 0,51
Se o potencial de ativação exceder um limiar definido (por exemplo, 0), o neurônio pós-sináptico gerará um potencial de ação, indicando que a característica desejada foi detectada na imagem.
Neste exemplo, os pesos sinápticos desempenham um papel crucial ao determinar a importância relativa de cada característica da imagem. Os sinais de entrada ponderados pelos pesos sinápticos são usados para calcular o potencial de ativação, que, se exceder o limiar, acionará a resposta do neurônio pós-sináptico. Isso permite que a rede neural tome decisões com base nas características detectadas na imagem.
A infraestrutura de hardware de uma rede neural artificial não tem nada de biológico; é a mesma da computação clássica (microprocessadores, placas gráficas, etc.).
A infraestrutura de software de uma rede neural artificial é diferente. Os algoritmos de aprendizado de máquina (machine learning) aprendem a partir de dados e ajustam seu comportamento com base nos exemplos fornecidos, enquanto os algoritmos de programação tradicional são baseados em instruções explícitas estáticas que não mudam por si mesmas. Nesse sentido, a IA é uma revolução, porque para escrever de forma estática as regras do ChatGPT 3.5 com seus 175 bilhões de parâmetros, teria levado milhares de anos.
Uma rede neural é organizada em camadas, onde cada neurônio artificial (função matemática) recebe entradas, realiza cálculos nessas entradas e gera uma saída. A primeira camada é a camada de entrada, que recebe os dados brutos (texto, imagem digital ou outros dados coletados). Atrás dela, há uma ou mais camadas ocultas (inacessíveis de fora), seguidas pela camada de saída, que produz as previsões.
Para fazer uma previsão, os dados são propagados da camada de entrada para a camada de saída. Cada neurônio soma suas entradas ponderadas, aplica uma função de ativação e passa o resultado para a próxima camada.
As funções de ativação introduzem não linearidades na rede. Isso significa que a relação entre as quantidades não é uma proporção constante, mas uma probabilidade. Isso é o que confere às redes neurais a capacidade de resolver uma variedade de problemas, desde o reconhecimento de imagens até a tradução automática, passando pela modelagem de linguagem natural.
Após fazer uma previsão, a rede compara seus próprios resultados com os rótulos corretos para medir o erro ou a diferença entre eles. Os rótulos corretos são um componente essencial do conjunto de treinamento de um modelo de aprendizado supervisionado. Eles são fornecidos para cada exemplo do conjunto de treinamento para permitir que o modelo aprenda a fazer previsões precisas.
Na próxima etapa, o algoritmo de retropropagação ajusta os pesos da rede (parâmetros internos que determinam como os neurônios respondem às entradas). Isso permite que ele encontre os valores que minimizam o erro do modelo. Esse processo é repetido até que a rede atinja um nível de desempenho satisfatório.
Na rede, também existem hiperparâmetros a serem ajustados, como a taxa de aprendizado, o tamanho do lote utilizado, a arquitetura da rede, a escolha da função de ativação nas camadas, etc.
Após avaliar o modelo para cada combinação, os pesquisadores escolhem os hiperparâmetros que oferecem o melhor desempenho nos dados de validação.
No final, o modelo treinado é avaliado com novos dados nunca antes vistos.
Suponhamos que temos à disposição um data center capaz de nos fornecer 100.000 imagens diferentes de 28x28 pixels em tons de cinza representando dígitos manuscritos de 0 a 9.
Nossa rede neural terá uma camada de entrada configurada para o tamanho das imagens (28x28 neurônios), uma ou mais camadas ocultas e uma camada de saída com 10 neurônios (já que há 10 dígitos possíveis: 0 a 9). Cada neurônio na camada de saída representa a probabilidade de que a imagem corresponda a um dígito específico.
Os pesos das conexões entre os neurônios são inicialmente definidos com valores aleatórios.
Os dados brutos, por exemplo, a imagem digital do número 3, são introduzidos na camada de entrada.
Para analisar as regiões locais da imagem, filtros de convolução deslizam sobre a imagem para extrair um mapa de características visuais hierárquicas. As primeiras camadas detectam bordas, enquanto as camadas superiores detectam padrões mais complexos.
Os dados se propagam pela rede seguindo as conexões ponderadas e aplicando funções de ativação. Em cada camada, operações matemáticas são realizadas para obter uma saída.
A camada de saída produz pontuações para cada dígito (0-9). Uma função transforma essas pontuações em probabilidades. O dígito com a maior probabilidade será a previsão da rede.
Em seguida, a rede comparará sua previsão com o rótulo real da imagem.
Uma função de custo mede a divergência entre as previsões do modelo e os rótulos reais.
Para isso, o erro é propagado no sentido inverso pela rede. A rede ajusta seus parâmetros (pesos e viés) em cada camada para minimizar o erro, por meio de algoritmos como o gradiente descendente.
Esse processo é repetido em um número muito grande de imagens de treinamento. A rede ajustará seus parâmetros em cada iteração para melhorar na classificação de dígitos manuscritos. Uma vez que a rede está treinada, ela é testada em um conjunto de dados distinto para avaliar seu desempenho.
Uma rede neural artificial é inspirada no funcionamento do cérebro humano: neurônios interconectados trocam sinais cujo impacto é modulado por pesos sinápticos. Em sua versão artificial, cada neurônio é uma função matemática que calcula uma soma ponderada de suas entradas, aplica uma função de ativação e transmite o resultado.
O aprendizado consiste em ajustar automaticamente os pesos sinápticos a partir de exemplos, por meio de um processo de retropropagação e otimização (gradiente descendente). É essa capacidade de aprender sem programação explícita de regras que distingue a IA da computação tradicional.
Na prática, a rede é organizada em camadas (entrada, ocultas, saída) e, após um treinamento iterativo com dados rotulados, torna-se capaz de fazer previsões sobre novos dados (reconhecimento de imagens, processamento de linguagem, etc.).
O neurônio biológico troca informações por meio de sinais elétricos e químicos (neurotransmissores). O neurônio artificial é uma abstração matemática (números, funções) que realiza cálculos. Ele não armazena dados, ao contrário dos bits computacionais, mas processa informações por meio de um potencial de ativação e pesos sinápticos.
O aprendizado acontece em três grandes etapas: primeiro, a rede faz uma previsão propagando os dados de entrada por suas camadas. Em seguida, ela compara sua previsão com o rótulo correto por meio de uma função de custo. Finalmente, um algoritmo de retropropagação ajusta os pesos sinápticos para minimizar o erro, repetindo esse processo em muitos exemplos.
As funções de ativação introduzem não linearidades na rede. Isso significa que a relação entre as quantidades não é uma proporção constante, mas uma probabilidade. Essa característica é o que permite às redes neurais resolver problemas complexos como reconhecimento de imagens, tradução automática ou modelagem de linguagem natural.
 Ferramentas de IA: como escolher?
Ferramentas de IA: como escolher? 
 IA Generativa vs AGI: Onde termina a imitação e onde começa a consciência?
IA Generativa vs AGI: Onde termina a imitação e onde começa a consciência?  Redes artificiais vs. redes biológicas: Dois sistemas, uma arquitetura comum
Redes artificiais vs. redes biológicas: Dois sistemas, uma arquitetura comum  Cérebro Humano e Inteligências Artificiais: Semelhanças e Diferenças
Cérebro Humano e Inteligências Artificiais: Semelhanças e Diferenças  AlphaGo contra AlphaGo Zero: Uma Revolução na Inteligência Artificial
AlphaGo contra AlphaGo Zero: Uma Revolução na Inteligência Artificial  O próximo passo das máquinas inteligentes
O próximo passo das máquinas inteligentes  Do Neurônio Biológico ao Neurônio Formal: Simplificação do Cérebro
Do Neurônio Biológico ao Neurônio Formal: Simplificação do Cérebro  Inteligência artificial: a explosão do gigantismo
Inteligência artificial: a explosão do gigantismo  Quando a inteligência artificial enlouquece!
Quando a inteligência artificial enlouquece!  Emergência da inteligência artificial: Ilusão de inteligência ou inteligência?
Emergência da inteligência artificial: Ilusão de inteligência ou inteligência?  Desafio e ameaça da Inteligência Artificial
Desafio e ameaça da Inteligência Artificial  Como as máquinas entendem, interpretam e geram linguagem de maneira semelhante aos humanos?
Como as máquinas entendem, interpretam e geram linguagem de maneira semelhante aos humanos?  Como funciona uma rede neural artificial?
Como funciona uma rede neural artificial?