
O conceito de "Self-Consuming Generative Models Go Mad" (modelos generativos autoconsumidores que enlouquecem) refere-se, no campo da inteligência artificial, à produção de dados de aprendizado pela própria IA.
Os modelos generativos são algoritmos que aprendem a gerar novos dados "imitando" um conjunto de dados de treinamento produzido por humanos. A produção de dados de aprendizado é custosa e demorada. Os dados devem ser coletados, limpos, anotados e formatados para que possam ser usados corretamente pela IA.
Os cientistas não resistiram à tentação de usar os dados sintéticos gerados pelos próprios modelos generativos para treinar novos modelos mais rapidamente.
A ideia central é criar um modelo generativo capaz de produzir seus próprios dados de aprendizado. Esse processo é então iterado, e o modelo se torna cada vez mais capaz de gerar dados complexos e inéditos.
As vantagens imaginadas são numerosas. Primeiro, o modelo não é limitado pela quantidade inicial de dados. Ele pode explorar domínios desconhecidos e descobrir novos conceitos. Graças ao seu aprendizado autossupervisionado, poderia melhorar seu desempenho de maneira iterativa. Por exemplo, poderia gerar estruturas moleculares inéditas como candidatas para novos medicamentos.
No entanto, existe um enorme desafio associado a essa abordagem.
O Self-Consuming Generative Models Go Mad é um fenômeno em que modelos de IA generativos treinam em dados sintéticos produzidos por outros modelos, criando loops autofágicos. Quando uma IA tenta aprender o conteúdo gerado por outra IA, ela enlouquece.
A repetição desse processo cria um loop autofágico em que os dados de aprendizado se tornam caóticos. Sem dados reais frescos, os futuros modelos generativos estão fadados ao fracasso.
Esse processo de autofagia leva a uma diminuição progressiva da qualidade e a uma diluição da diversidade no conteúdo gerado. O modelo então produz saídas incoerentes e redundantes.
Se o modelo não for exposto a uma variedade suficiente de exemplos, ele não consegue aprender padrões significativos e gera produções repetitivas.
Ao se concentrar apenas em sua própria produção, ele se afasta da realidade e gera resultados aberrantes.
Por fim, sofre de overfitting: memoriza detalhes insignificantes e perde sua capacidade de generalizar. Ele então reproduz seus próprios viéses infinitamente.
Em alguns cenários, os modelos generativos podem "enlouquecer" ou malfuncionar de maneira inesperada, até mesmo autodestrutiva. Por exemplo, um modelo pode priorizar a novidade a ponto de explorar territórios cada vez mais instáveis.
A falta de regulamentação expõe o modelo a um descontrole em que os conteúdos se tornam extremos, ofensivos ou chocantes. Corremos então o risco de não entender mais os resultados gerados pelo modelo.
Essa noção especulativa destaca as preocupações associadas ao uso de modelos de IA autônomos ou mal controlados. É uma reflexão importante sobre como conceber e regular essas tecnologias de forma responsável.
Em resumo, quando os modelos de IA treinam em seus próprios dados, eles se isolam do mundo real e de seus valores. Assim como a consanguinidade na natureza, onde a reprodução entre indivíduos geneticamente próximos leva ao empobrecimento do patrimônio genético e ao acúmulo de defeitos, esse fechamento cognitivo provoca um empobrecimento intelectual e uma deriva progressiva: as IAs enlouquecem!
 O Grande Filtro da Evolução: a chave do paradoxo de Fermi
O Grande Filtro da Evolução: a chave do paradoxo de Fermi  Por que o girassol vira-se para o Sol? Uma resposta pelo Lagrangiano
Por que o girassol vira-se para o Sol? Uma resposta pelo Lagrangiano  População mundial 2026: tendências demográficas por continente
População mundial 2026: tendências demográficas por continente  Por que a vida emerge do desequilíbrio e desaparece no equilíbrio termodinâmico
Por que a vida emerge do desequilíbrio e desaparece no equilíbrio termodinâmico  O Espectro Eletromagnético e a Visão: O que nossos olhos percebem do nosso planeta
O Espectro Eletromagnético e a Visão: O que nossos olhos percebem do nosso planeta  Próprio e Não-Próprio: Uma Leitura Física Simplificada da Identidade
Próprio e Não-Próprio: Uma Leitura Física Simplificada da Identidade 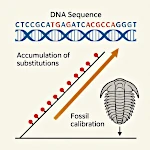 O Relógio Molecular: Do Acaso das Mutations à Medida do Tempo
O Relógio Molecular: Do Acaso das Mutations à Medida do Tempo  As Pegadas de White Sands: Primeiros Passos da América
As Pegadas de White Sands: Primeiros Passos da América 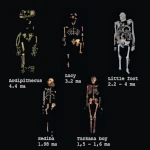 Hominíneos: Aparecimento, Expansão e Extinções
Hominíneos: Aparecimento, Expansão e Extinções  Grandes Catástrofes Naturais: Quais São as Ameaças Mais Prováveis?
Grandes Catástrofes Naturais: Quais São as Ameaças Mais Prováveis?  Os Grandes Colapsos Civilizacionais: Períodos-Chave e Causas
Os Grandes Colapsos Civilizacionais: Períodos-Chave e Causas  IA Generativa vs AGI: Onde termina a imitação e onde começa a consciência?
IA Generativa vs AGI: Onde termina a imitação e onde começa a consciência?  Nascimentos em Declínio: Catástrofe Demográfica ou Evolução Natural?
Nascimentos em Declínio: Catástrofe Demográfica ou Evolução Natural?  Seleção Natural vs. Acaso: Por que a Evolução não é uma Loteria?
Seleção Natural vs. Acaso: Por que a Evolução não é uma Loteria?  E se a Vida Partisse da Terra? Uma Revolução na Teoria da Panspermia
E se a Vida Partisse da Terra? Uma Revolução na Teoria da Panspermia  A Grande Bifurcação que vai Revolucionar o Nosso Mundo: Sobrevivência ou Colapso?
A Grande Bifurcação que vai Revolucionar o Nosso Mundo: Sobrevivência ou Colapso?  Química primordial: Onde nascem as primeiras moléculas orgânicas?
Química primordial: Onde nascem as primeiras moléculas orgânicas?  CO e CO₂: Dois Gases, Dois Riscos, Dois Mecanismos Biológicos
CO e CO₂: Dois Gases, Dois Riscos, Dois Mecanismos Biológicos  Sincronização Espontânea: um Fenômeno Universal, da Física ao Vivo
Sincronização Espontânea: um Fenômeno Universal, da Física ao Vivo  Redes artificiais vs. redes biológicas: Dois sistemas, uma arquitetura comum
Redes artificiais vs. redes biológicas: Dois sistemas, uma arquitetura comum  Cérebro Humano e Inteligências Artificiais: Semelhanças e Diferenças
Cérebro Humano e Inteligências Artificiais: Semelhanças e Diferenças  Desafio temporal: como ilustrar um bilhão de anos?
Desafio temporal: como ilustrar um bilhão de anos?  Os Três Componentes Essenciais para a Emergência da Vida
Os Três Componentes Essenciais para a Emergência da Vida  Por que o Gênero Homo Esteve à Beira da Extinção Há 900.000 Anos?
Por que o Gênero Homo Esteve à Beira da Extinção Há 900.000 Anos?  AlphaGo contra AlphaGo Zero: Uma Revolução na Inteligência Artificial
AlphaGo contra AlphaGo Zero: Uma Revolução na Inteligência Artificial  O próximo passo das máquinas inteligentes
O próximo passo das máquinas inteligentes  O primeiro passo para o surgimento da vida
O primeiro passo para o surgimento da vida  Do Neurônio Biológico ao Neurônio Formal: Simplificação do Cérebro
Do Neurônio Biológico ao Neurônio Formal: Simplificação do Cérebro  A biosfera de sombra
A biosfera de sombra  Declínio do Antropocentrismo
Declínio do Antropocentrismo  Inteligência artificial: a explosão do gigantismo
Inteligência artificial: a explosão do gigantismo  Quando a inteligência artificial enlouquece!
Quando a inteligência artificial enlouquece!  Emergência da inteligência artificial: Ilusão de inteligência ou inteligência?
Emergência da inteligência artificial: Ilusão de inteligência ou inteligência?  O caranguejo-ferradura, um fóssil vivo!
O caranguejo-ferradura, um fóssil vivo!  Bioassinaturas ou presença de vida no Universo
Bioassinaturas ou presença de vida no Universo  Desafio e ameaça da Inteligência Artificial
Desafio e ameaça da Inteligência Artificial  Como as máquinas entendem, interpretam e geram linguagem de maneira semelhante aos humanos?
Como as máquinas entendem, interpretam e geram linguagem de maneira semelhante aos humanos?  Como funciona uma rede neural artificial?
Como funciona uma rede neural artificial?  Origem da vida na Terra: teoria da Panspermia
Origem da vida na Terra: teoria da Panspermia  Origem da Vida na Terra: Teoria dos Fumadores Brancos
Origem da Vida na Terra: Teoria dos Fumadores Brancos  Por que 37 graus Celsius?
Por que 37 graus Celsius?  Estamos sozinhos no cosmos? Entre ciência e especulação
Estamos sozinhos no cosmos? Entre ciência e especulação  Rastros de Vida no Gelo: O Surgimento dos Mamutes Pré-Históricos
Rastros de Vida no Gelo: O Surgimento dos Mamutes Pré-Históricos  O Dryas: A mini era glacial que dizimou a megafauna
O Dryas: A mini era glacial que dizimou a megafauna  As Duas Grandes Glaciações: Sobreviver nos Oceanos de uma Terra Gelada
As Duas Grandes Glaciações: Sobreviver nos Oceanos de uma Terra Gelada  Regeneração em Animais após Amputação: O Recrescimento Orgânico
Regeneração em Animais após Amputação: O Recrescimento Orgânico  Nos Confins da Vida: Mephisto, Verme das Profundezas Infernais
Nos Confins da Vida: Mephisto, Verme das Profundezas Infernais  Descoberta de fulerenos sólidos no espaço
Descoberta de fulerenos sólidos no espaço  A Marcha Humana: As Origens do Bipedalismo nos Hominídeos
A Marcha Humana: As Origens do Bipedalismo nos Hominídeos  A passagem entre o inerte e o vivo
A passagem entre o inerte e o vivo  A Grande Narrativa da Complexidade: Das Partículas Elementares aos Primeiros Organismos
A Grande Narrativa da Complexidade: Das Partículas Elementares aos Primeiros Organismos  Karabo: Uma janela para a evolução humana
Karabo: Uma janela para a evolução humana  Megapod usa calor vulcânico
Megapod usa calor vulcânico  Ardipithecus: O hominídeo etíope de 4,4 milhões de anos
Ardipithecus: O hominídeo etíope de 4,4 milhões de anos  Seleção Natural: A Mariposa do Bétula
Seleção Natural: A Mariposa do Bétula  O Ordoviciano: A era dos corais, trilobitas e graptólitos
O Ordoviciano: A era dos corais, trilobitas e graptólitos  Água Líquida, Muito Mais Que um Solvente: Um Acelerador de Reações Químicas
Água Líquida, Muito Mais Que um Solvente: Um Acelerador de Reações Químicas  Neandertal: O Primo Desaparecido da Humanidade
Neandertal: O Primo Desaparecido da Humanidade  Asimo, o futuro humanóide
Asimo, o futuro humanóide  Quais Condições Permitiram a Emergência da Vida?
Quais Condições Permitiram a Emergência da Vida?  Paradoxo de Fermi e caverna de Platão: Estamos sozinhos ou cegos?
Paradoxo de Fermi e caverna de Platão: Estamos sozinhos ou cegos?  Tardígrados: Criaturas indestrutíveis que desafiam as leis da biologia
Tardígrados: Criaturas indestrutíveis que desafiam as leis da biologia  Toumaï: Um dos hominíneos mais antigos conhecidos
Toumaï: Um dos hominíneos mais antigos conhecidos  A Árvore da Vida: Bilhões de espécies extintas e uma única comunidade ancestral
A Árvore da Vida: Bilhões de espécies extintas e uma única comunidade ancestral  A Vida nas Zonas Abissais: A Adaptação Extrema das Criaturas
A Vida nas Zonas Abissais: A Adaptação Extrema das Criaturas  Cianobactérias e a Crise do Oxigênio: Uma Catástrofe Ecológica Primordial
Cianobactérias e a Crise do Oxigênio: Uma Catástrofe Ecológica Primordial  Da Matéria à Vida: A Fronteira Difusa da Emergência Biológica
Da Matéria à Vida: A Fronteira Difusa da Emergência Biológica  O Sapo Mais Pequeno do Mundo: Segredos Fisiológicos de um Microvertebrado
O Sapo Mais Pequeno do Mundo: Segredos Fisiológicos de um Microvertebrado  A explicação da Pequena Idade do Gelo
A explicação da Pequena Idade do Gelo  A Luz da Vida: uma Biossignatura Revelada pela Lua
A Luz da Vida: uma Biossignatura Revelada pela Lua  Luz Viva: Os Segredos Deslumbrantes da Bioluminescência
Luz Viva: Os Segredos Deslumbrantes da Bioluminescência  Além dos nossos sentidos, as grandes revoluções científicas
Além dos nossos sentidos, as grandes revoluções científicas  A Sopa Primordial: Berço Químico da Vida Terrestre
A Sopa Primordial: Berço Químico da Vida Terrestre  População Mundial: De Um Bilhão de Humanos à Saturação Demográfica
População Mundial: De Um Bilhão de Humanos à Saturação Demográfica  Ecologia e colapso: o caso da Ilha de Páscoa
Ecologia e colapso: o caso da Ilha de Páscoa  Fractais:
Estruturas Universais Auto-organizadas
Fractais:
Estruturas Universais Auto-organizadas