
The concept of "Self-Consuming Generative Models Go Mad" (self-consuming generative models going mad) refers, in the field of artificial intelligence, to the production of training data by the AI itself.
Generative models are algorithms that learn to generate new data by "imitating" a training dataset produced by humans. Producing training data is costly and time-consuming. Data must be collected, cleaned, annotated, and formatted so that it can be used correctly by the AI.
Scientists could not resist the temptation to use synthetic data generated by generative models themselves to train new models more quickly.
The central idea is to create a generative model capable of producing its own training data. This process is then iterated, with the model becoming increasingly capable of generating complex and novel data.
The imagined advantages are numerous. First, the model is not limited by the initial amount of data. It can explore unknown domains and discover new concepts. Thanks to its self-supervised learning, it could iteratively improve its performance. For example, it could generate novel molecular structures as candidates for new drugs.
However, there is a huge challenge associated with this approach.
Self-Consuming Generative Models Go Mad is a phenomenon where generative AI models train on synthetic data produced by other models, creating self-consuming loops. When an AI tries to learn content generated by another AI, it goes mad.
Repeating this process creates a self-consuming loop where the training data becomes chaotic. Without fresh real data, future generative models are doomed to failure.
This autophagy process leads to a gradual decrease in quality and a dilution of diversity in the generated content. The model then produces incoherent and redundant outputs.
If the model is not exposed to a sufficient variety of examples, it fails to learn significant patterns and generates repetitive outputs.
By focusing only on its own production, it moves away from reality and generates aberrant results.
Finally, it suffers from overfitting: it memorizes insignificant details and loses its ability to generalize. It then reproduces its own biases infinitely.
In some scenarios, generative models can become "mad" or malfunction in unexpected, even self-destructive ways. For example, a model might prioritize novelty to the point of exploring increasingly unstable territories.
The lack of regulation exposes the model to runaway behavior, where content becomes extreme, offensive, or shocking. We then risk no longer understanding the results generated by the model.
This speculative notion highlights the concerns associated with the use of autonomous or poorly controlled AI models. It is an important reflection on how to design and regulate these technologies responsibly.
In summary, when AI models train on their own data, they isolate themselves from the real world and its values. Like inbreeding in nature, where reproduction between genetically close individuals leads to a depletion of the gene pool and the accumulation of defects, this cognitive closure causes intellectual impoverishment and progressive drift: AIs go mad!
 The Great Filter of Evolution: The Key to the Fermi Paradox
The Great Filter of Evolution: The Key to the Fermi Paradox  Why Does the Sunflower Turn Toward the Sun? An Answer Through the Lagrangian
Why Does the Sunflower Turn Toward the Sun? An Answer Through the Lagrangian  World Population 2026: Demographic Trends by Continent
World Population 2026: Demographic Trends by Continent  Why Life Emerges from Imbalance and Dies at Thermodynamic Equilibrium
Why Life Emerges from Imbalance and Dies at Thermodynamic Equilibrium  The Electromagnetic Spectrum and Vision: What Our Eyes Perceive of Our Planet
The Electromagnetic Spectrum and Vision: What Our Eyes Perceive of Our Planet  Self and Non-Self: A Simplified Physical Reading of Identity
Self and Non-Self: A Simplified Physical Reading of Identity 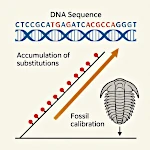 The Molecular Clock: From Random Mutations to Measuring Time
The Molecular Clock: From Random Mutations to Measuring Time  White Sands Footprints: America's First Steps
White Sands Footprints: America's First Steps 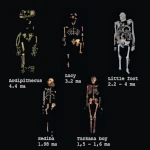 Hominins: Appearance, Expansion, and Extinctions
Hominins: Appearance, Expansion, and Extinctions  Major Natural Disasters: What Are the Most Likely Threats?
Major Natural Disasters: What Are the Most Likely Threats?  Major Civilizational Collapses: Key Periods and Causes
Major Civilizational Collapses: Key Periods and Causes  Generative AI vs AGI: Where does imitation end and consciousness begin?
Generative AI vs AGI: Where does imitation end and consciousness begin?  Declining Births: Demographic Catastrophe or Natural Evolution?
Declining Births: Demographic Catastrophe or Natural Evolution?  Natural Selection vs. Chance: Why Evolution is Not a Lottery?
Natural Selection vs. Chance: Why Evolution is Not a Lottery?  What if Life Originated from Earth? A Revolution in the Theory of Panspermia
What if Life Originated from Earth? A Revolution in the Theory of Panspermia  The Great Bifurcation that will Disrupt Our World: Survival or Collapse?
The Great Bifurcation that will Disrupt Our World: Survival or Collapse?  Primordial Chemistry: Where Do the First Organic Molecules Originate?
Primordial Chemistry: Where Do the First Organic Molecules Originate?  CO and CO₂: Two Gases, Two Risks, Two Biological Mechanisms
CO and CO₂: Two Gases, Two Risks, Two Biological Mechanisms  Spontaneous Synchronization: A Universal Phenomenon, from Physics to Life
Spontaneous Synchronization: A Universal Phenomenon, from Physics to Life  Artificial networks vs biological networks: Two systems, one common architecture
Artificial networks vs biological networks: Two systems, one common architecture  Human Brain and Artificial Intelligences: Similarities and Differences
Human Brain and Artificial Intelligences: Similarities and Differences  Time Challenge: How to Illustrate a Billion Years?
Time Challenge: How to Illustrate a Billion Years?  The Three Essential Components for the Emergence of Life
The Three Essential Components for the Emergence of Life  Why Did the Genus Homo Nearly Go Extinct 900,000 Years Ago?
Why Did the Genus Homo Nearly Go Extinct 900,000 Years Ago?  AlphaGo vs AlphaGo Zero: A Revolution in Artificial Intelligence
AlphaGo vs AlphaGo Zero: A Revolution in Artificial Intelligence  The Next Step for Intelligent Machines
The Next Step for Intelligent Machines  The First Step Towards the Emergence of Life
The First Step Towards the Emergence of Life  From Biological Neuron to Formal Neuron: Simplifying the Brain
From Biological Neuron to Formal Neuron: Simplifying the Brain  The shadow biosphere
The shadow biosphere  Decline of Anthropocentrism
Decline of Anthropocentrism  Artificial intelligence: the explosion of gigantism
Artificial intelligence: the explosion of gigantism  When AI models train on their own data, they go mad!
When AI models train on their own data, they go mad!  Emergence of artificial intelligence: Illusion of intelligence or intelligence?
Emergence of artificial intelligence: Illusion of intelligence or intelligence?  The horseshoe crab, a living fossil!
The horseshoe crab, a living fossil!  Biosignatures or presence of life in the Universe
Biosignatures or presence of life in the Universe  Challenge and threat of Artificial Intelligence
Challenge and threat of Artificial Intelligence  How do machines understand, interpret and generate language in a similar way to humans?
How do machines understand, interpret and generate language in a similar way to humans?  How does an artificial neural network work?
How does an artificial neural network work?  Origin of life on Earth: Panspermia theory
Origin of life on Earth: Panspermia theory  Origin of life on Earth: White smoker theory
Origin of life on Earth: White smoker theory  Why 37 degrees Celsius?
Why 37 degrees Celsius?  Are We Alone in the Cosmos? Between Science and Speculation
Are We Alone in the Cosmos? Between Science and Speculation  Traces of Life in the Ice: The Emergence of Prehistoric Mammoths
Traces of Life in the Ice: The Emergence of Prehistoric Mammoths  The Younger Dryas: The Mini Ice Age That Wiped Out the Megafauna
The Younger Dryas: The Mini Ice Age That Wiped Out the Megafauna  The Two Great Ice Ages: Surviving in the Oceans of a Frozen Earth
The Two Great Ice Ages: Surviving in the Oceans of a Frozen Earth  Regeneration in Animals Following Amputation: Organic Regrowth
Regeneration in Animals Following Amputation: Organic Regrowth  At the Limits of Life: Mephisto, Worm of the Infernal Depths
At the Limits of Life: Mephisto, Worm of the Infernal Depths  Discovery of solid buckyballs in space
Discovery of solid buckyballs in space  Human Walking: The Origins of Bipedalism in Hominids
Human Walking: The Origins of Bipedalism in Hominids  The passage between the inert and the living
The passage between the inert and the living  The Great Story of Complexity: From Elementary Particles to the First Organisms
The Great Story of Complexity: From Elementary Particles to the First Organisms  Karabo: A Window into Human Evolution
Karabo: A Window into Human Evolution  Megapod uses volcanic heat
Megapod uses volcanic heat  Ardipithecus: The 4.4-Million-Year-Old Ethiopian Hominid
Ardipithecus: The 4.4-Million-Year-Old Ethiopian Hominid  Natural Selection: The Peppered Moth
Natural Selection: The Peppered Moth  The Ordovician: The Era of Corals, Trilobites, and Graptolites
The Ordovician: The Era of Corals, Trilobites, and Graptolites  Liquid Water, Much More Than a Solvent: A Catalyst for Chemical Reactions
Liquid Water, Much More Than a Solvent: A Catalyst for Chemical Reactions  Neanderthal: Humanity's Lost Cousin
Neanderthal: Humanity's Lost Cousin  Asimo the future humanoid
Asimo the future humanoid  What Conditions Allowed the Emergence of Life?
What Conditions Allowed the Emergence of Life?  Fermi Paradox and Plato's Cave: Are We Alone or Blind?
Fermi Paradox and Plato's Cave: Are We Alone or Blind?  Tardigrades: Indestructible Creatures That Defy the Laws of Biology
Tardigrades: Indestructible Creatures That Defy the Laws of Biology  Toumaï: One of the Oldest Known Hominins
Toumaï: One of the Oldest Known Hominins  The Tree of Life: Billions of Extinct Species and a Single Ancestral Community
The Tree of Life: Billions of Extinct Species and a Single Ancestral Community  Life in the Abyss: The Extreme Adaptation of Creatures
Life in the Abyss: The Extreme Adaptation of Creatures  Cyanobacteria and the Oxygen Crisis: A Primordial Ecological Catastrophe
Cyanobacteria and the Oxygen Crisis: A Primordial Ecological Catastrophe  From Matter to Life: The Blurred Frontier of Biological Emergence
From Matter to Life: The Blurred Frontier of Biological Emergence  The Smallest Frog in the World: Physiological Secrets of a Microvertebrate
The Smallest Frog in the World: Physiological Secrets of a Microvertebrate  The explanation of the Little Ice Age
The explanation of the Little Ice Age  The Light of Life: A Biosignature Revealed by the Moon
The Light of Life: A Biosignature Revealed by the Moon  Living Light: The Dazzling Secrets of Bioluminescence
Living Light: The Dazzling Secrets of Bioluminescence  Beyond our senses, the great scientific revolutions
Beyond our senses, the great scientific revolutions  The Primordial Soup: Chemical Cradle of Terrestrial Life
The Primordial Soup: Chemical Cradle of Terrestrial Life  World Population: From One Billion Humans to Demographic Saturation
World Population: From One Billion Humans to Demographic Saturation  Ecology and Collapse: The Case of Easter Island
Ecology and Collapse: The Case of Easter Island  Fractals:
Universally Self-Organized Structures
Fractals:
Universally Self-Organized Structures