Un réseau de neurones artificiels est un système informatique composé d'unités de traitement mathématiques (neurones artificiels) organisées en couches interconnectées. Inspiré du fonctionnement du cerveau humain, il apprend à partir de données en ajustant ses « poids synaptiques » pour effectuer des tâches comme la reconnaissance d'images ou le traitement du langage, sans programmation explicite de toutes les règles.
Pour aborder le fonctionnement des réseaux de neurones artificiels, il est nécessaire de comprendre le sens de l'intelligence artificielle (IA). L'IA consiste à créer des systèmes informatiques capables d'automatiser des tâches sans l'intervention humaine, mais aussi d'apprendre, de s'adapter, de s'améliorer, de communiquer et surtout de prendre des décisions. Dans ce sens, l'IA cherche à reproduire des aspects de l'intelligence humaine.
La définition de l'intelligence est très discutable, mais le sens qui va nous intéresser ici c'est celui de fonctions contrôlées par le cerveau. En effet, qu'elles soient mécaniques comme la marche ou cognitives comme la prise de décision, l'architecture des fonctions reste la même dans toutes les aires cérébrales de notre cerveau. De plus, toutes les fonctions sont d'égale importance, sans distinction entre celles considérées comme nobles ou moins nobles. Elles sont toutes réalisées avec la même complexité de calculs, à travers un énorme réseau de milliards de neurones interconnectés entre eux pour échanger de l'information. L'information est échangée par le biais de signaux électriques et chimiques.
Dans le cerveau humain, le processus de communication entre neurones est le suivant:
- Lorsque les signaux électriques, initiés au niveau de la membrane cellulaire du neurone, atteignent un seuil critique, ils déclenchent une brève impulsion électrique que l'on appelle "potentiel d'action". Les potentiels d'action voyagent le long de l'axone jusqu'à la synapse du neurone.
- Au niveau de la synapse (points de contact entre les neurones) les potentiels d'action déclenchent la libération de molécules chimiques, appelées "neurotransmetteurs".
- Les neurotransmetteurs se lient ensuite aux récepteurs situés sur la membrane du neurone postsynaptique (le neurone récepteur). Cette liaison chimique déclenche une réponse électrique dans le neurone postsynaptique.
- Le neurone postsynaptique intègre toutes les entrées qu'il reçoit des neurones émetteurs, et si le seuil critique est atteint, il génère à son tour un potentiel d'action qui se propage le long de son propre axone, poursuivant ainsi la transmission de l'information dans le réseau.
Selon les types de neurotransmetteurs libérés, l'activité présynaptique peut avoir un effet excitateur ou inhibiteur sur l'activité électrique du neurone postsynaptique. Cela rend le déclenchement d'un potentiel d'action plus ou moins probable.
Ce processus complexe est à la base du fonctionnement du cerveau et de la cognition humaine. C'est à partir de ce processus que les chercheurs vont élaborer un modèle d'intelligence artificielle, très simple au début puis de plus en plus sophistiqué au fur et à mesure de l'avancée technologique.
Le neurone artificiel est l'unité de base d'un réseau de neurones artificiels. Un réseau de neurones artificiels est composé d'une succession de couches de neurones interconnectés dont chacune prend ses entrées sur les sorties de la couche précédente.
Les neurones artificiels ne sont pas des bits informatiques (0 ou 1), mais plutôt des abstractions mathématiques (nombres, opérations, fonctions, équations, matrices, ensemble, probabilité, etc.). En d'autres termes, ce sont des unités de traitement qui effectuent des opérations mathématiques sur les données qui leur sont présentées. Elles ne stockent pas de données alors que les bits informatiques sont à la base du stockage de l'information numérique.
Dans un réseau de neurones artificiels, chaque neurone est caractérisé par un niveau d'activité capturé par une variable appelée le "potentiel d'activation". La synapse du neurone est caractérisée par une autre variable appelée le "poids synaptique".
- Le potentiel d'activation représente l'état électrique du neurone postsynaptique à un moment donné. Il est calculé en sommant les signaux d'entrée provenant des neurones présynaptiques, chaque signal étant modulé par le poids synaptique correspondant. Le potentiel d'activation peut varier de manière continue dans une plage allant de valeurs négatives à positives, en fonction de l'intensité des signaux entrants.
- Les poids synaptiques déterminent si une connexion synaptique est excitatrice, inhibitrice ou nulle. Les poids modulent l'impact des signaux d'entrée sur le potentiel d'activation. Les poids positifs augmentent l'activité, les poids négatifs la réduisent, et les poids nuls n'ont pas d'effet.
Le potentiel d'activation résulte de la combinaison des signaux d'entrée pondérés par les poids synaptiques. Ce potentiel est ensuite soumis à une fonction d'activation, qui introduit une non-linéarité et détermine si le neurone postsynaptique génère une réponse (potentiel d'action) ou non. En fin de compte, ces mécanismes permettent au neurone de traiter l'information et de répondre aux stimuli de manière adaptative. Le fonctionnement de ces variables est fondamental pour la modélisation du comportement des neurones, tant dans les réseaux de neurones biologiques que dans les réseaux de neurones artificiels.
Imaginons un réseau de neurones artificiels utilisé pour la classification d'images. Ce réseau comporte un neurone postsynaptique qui reçoit des connexions en provenance de trois neurones présynaptiques. Chacun de ces trois neurones présynaptiques est associé à une caractéristique spécifique de l'image que le réseau analyse, par exemple, la présence de lignes verticales, de lignes horizontales et de courbes.
Le neurone postsynaptique a un potentiel d'activation initial de 0.
Lorsque les trois neurones présynaptiques envoient leurs signaux, chaque signal est multiplié par le poids synaptique associé à la connexion correspondante. Supposons que les poids synaptiques soient les suivants:
- Poids synaptique pour la caractéristique des lignes verticales: +0,5
- Poids synaptique pour la caractéristique des lignes horizontales: -0,3
- Poids synaptique pour la caractéristique des courbes: +0,2
Les signaux des trois neurones présynaptiques sont pondérés par les poids synaptiques respectifs et sommés.
Si nous avons les signaux suivants:
- Signal pour les lignes verticales: 1
- Signal pour les lignes horizontales: 0,5
- Signal pour les courbes: 0,8
Le potentiel d'activation serait calculé comme suit:
Potentiel d'activation = (1 * 0,5) + (0,5 * (-0,3)) + (0,8 * 0,2) = 0,5 - 0,15 + 0,16 = 0,51
Si le potentiel d'activation dépasse un seuil défini (par exemple 0), le neurone postsynaptique génèrera un potentiel d'action, indiquant que la caractéristique recherchée a été détectée dans l'image.
Dans cet exemple, les poids synaptiques jouent un rôle crucial en déterminant l'importance relative de chaque caractéristique de l'image. Les signaux d'entrée pondérés par les poids synaptiques sont utilisés pour calculer le potentiel d'activation, qui, s'il dépasse le seuil, déclenchera la réponse du neurone postsynaptique. Cela permet au réseau de neurones de prendre des décisions en fonction des caractéristiques détectées dans l'image.
L'infrastructure hardware d'un réseau de neurones artificiels n'a rien de biologique, c'est la même que celle de l'informatique classique (microprocesseurs, cartes graphiques, etc.).
L'infrastructure software d'un réseau de neurones artificiels est différente. Les algorithmes d'apprentissage (machine learning) apprennent à partir de données et ajustent leur comportement en fonction des exemples fournis, alors que les algorithmes de programmation traditionnelle sont basés sur des instructions explicites statiques qui ne changent pas d'elles-mêmes. C'est en ce sens que l'IA est une révolution car pour écrire de façon statique les règles de ChatGPT 3.5 avec ses 175 milliards de paramètres, il aurait fallu des milliers d'années.
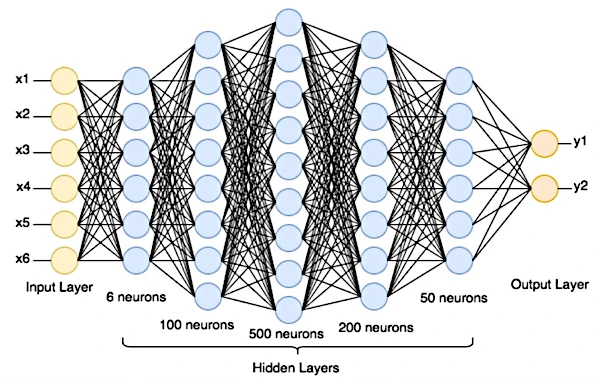
Un réseau de neurones est organisé en couches où chaque neurone artificiel (fonction mathématique) reçoit des entrées, effectue des calculs sur ces entrées et génère une sortie. La première couche est la couche d'entrée, qui reçoit les données brutes (texte, image numérique ou autres données collectées). Derrière, il y a une ou plusieurs couches cachées (non accessibles depuis l'extérieur), suivies de la couche de sortie qui produit les prédictions.
Pour effectuer une prédiction, les données sont propagées de la couche d'entrée à la couche de sortie. Chaque neurone somme ses entrées pondérées, applique une fonction d'activation, et passe le résultat à la couche suivante.
Les fonctions d'activation introduisent des non-linéarités dans le réseau. Cela signifie que la relation entre les quantités n'est pas une proportion constante mais une probabilité. C'est ce qui confère aux réseaux de neurones leur capacité à résoudre une variété de problèmes, de la reconnaissance d'images à la traduction automatique, en passant par la modélisation du langage naturel.
Après avoir effectué une prédiction, le réseau compare ses propres résultats aux étiquettes correctes afin de mesurer l'erreur ou la différence entre les deux. Les étiquettes correctes sont une composante essentielle de l'ensemble d'entrainement d'un modèle d'apprentissage supervisé. Elles sont fournies pour chaque exemple de l'ensemble d'entrainement afin de permettre au modèle d'apprendre à faire des prédictions précises.
Dans l'étape d'après, l'algorithme de rétro propagation ajuste les poids du réseau (paramètres internes qui déterminent comment les neurones réagissent aux entrées). Cela lui permet de trouver les valeurs qui minimisent l'erreur du modèle. Ce processus se répète jusqu'à ce que le réseau atteigne un niveau de performance satisfaisant.
Dans le réseau, il existe également des hyper paramètres à régler, tels que le taux d'apprentissage, la taille du lot utilisé, l'architecture du réseau, le choix de la fonction d'activation dans les couches, etc.
Après avoir évalué le modèle pour chaque combinaison, les chercheurs choisissent les hyper paramètres qui donnent les meilleures performances sur les données de validation.
En fin de compte, le modèle entrainé est évalué sur de nouvelles données jamais vues.
Supposons que nous avons à disposition un data center capable de nous fournir 100 000 images différentes de 28x28 pixels en niveaux de gris représentant des chiffres manuscrits de 0 à 9.
Notre réseau de neurones aura une couche d'entrée configurée à la taille des images (28x28 neurones), une ou plusieurs couches cachées, et une couche de sortie avec 10 neurones (car il y a 10 chiffres possibles: 0 à 9). Chaque neurone dans la couche de sortie représente la probabilité que l'image corresponde à un chiffre particulier.
Les poids des connexions entre les neurones sont initialement définis à des valeurs aléatoires.
La donnée brute par exemple l'image numérique du 3 est introduite dans la couche d'entrée.
Pour analyser les régions locales de l'image, des filtres de convolution glissent sur l'image pour en extraire une carte de caractéristiques visuelles hiérarchiques. Les premières couches détectent des bords, les couches supérieures des motifs plus complexes.
Les données se propagent à travers le réseau en suivant les connexions pondérées et en appliquant des fonctions d'activation. À chaque couche, des opérations mathématiques sont effectuées pour obtenir une sortie.
La couche de sortie produit des scores pour chaque chiffre (0-9). Une fonction transforme ces scores en probabilités. Le chiffre avec la probabilité la plus élevée sera la prédiction du réseau.
Ensuite le réseau va comparer sa prédiction avec l'étiquette réelle de l'image.
Une fonction de coût mesure la divergence entre les prédictions du modèle et les étiquettes réelles.
Pour cela, l'erreur est propagée en sens inverse à travers le réseau. Le réseau ajuste ses paramètres (poids et biais) dans chaque couche pour minimiser l'erreur, via des algorithmes comme la descente de gradient.
Ce processus est répété sur un très grand nombre d'images d'entrainement. Le réseau va ajuster ses paramètres à chaque itération pour s'améliorer dans la classification des chiffres manuscrits. Une fois le réseau entrainé, il est testé sur un ensemble de données distinct pour évaluer sa performance.
Un réseau de neurones artificiels s'inspire du fonctionnement du cerveau humain : des neurones interconnectés échangent des signaux dont l'impact est modulé par des poids synaptiques. Dans sa version artificielle, chaque neurone est une fonction mathématique qui calcule une somme pondérée de ses entrées, applique une fonction d'activation, et transmet le résultat.
L'apprentissage consiste à ajuster automatiquement les poids synaptiques à partir d'exemples, via un processus de rétropropagation et d'optimisation (descente de gradient). C'est cette capacité à apprendre sans programmation explicite des règles qui distingue l'IA de l'informatique traditionnelle.
En pratique, le réseau est organisé en couches (entrée, cachées, sortie) et, après un entraînement itératif sur des données étiquetées, il devient capable de faire des prédictions sur des données nouvelles (reconnaissance d'images, traitement du langage, etc.).
Le neurone biologique échange des informations via des signaux électriques et chimiques (neurotransmetteurs). Le neurone artificiel est une abstraction mathématique (nombres, fonctions) qui effectue des calculs. Il ne stocke pas de données contrairement aux bits informatiques, mais traite l'information via un potentiel d'activation et des poids synaptiques.
L'apprentissage se fait en trois grandes étapes : d'abord, le réseau effectue une prédiction en propageant les données d'entrée à travers ses couches. Ensuite, il compare sa prédiction à l'étiquette correcte via une fonction de coût. Enfin, un algorithme de rétropropagation ajuste les poids synaptiques pour minimiser l'erreur, répétant ce processus sur de nombreux exemples.
Les fonctions d'activation introduisent des non-linéarités dans le réseau. Cela signifie que la relation entre les quantités n'est pas une proportion constante mais une probabilité. C'est cette caractéristique qui permet aux réseaux de neurones de résoudre des problèmes complexes comme la reconnaissance d'images, la traduction automatique ou la modélisation du langage naturel.
 Outils d’intelligence artificielle : comment choisir ?
Outils d’intelligence artificielle : comment choisir ? 
 IA Générative vs AGI: Où s’arrête l’imitation, où commence la conscience?
IA Générative vs AGI: Où s’arrête l’imitation, où commence la conscience?  Réseaux artificiels vs réseaux biologiques: Deux systèmes, une architecture commune
Réseaux artificiels vs réseaux biologiques: Deux systèmes, une architecture commune  Cerveau Humain et Intelligences Artificielles: Similitudes et Différences
Cerveau Humain et Intelligences Artificielles: Similitudes et Différences  AlphaGo contre AlphaGo Zero: Une Révolution dans l'Intelligence Artificielle
AlphaGo contre AlphaGo Zero: Une Révolution dans l'Intelligence Artificielle  La prochaine étape des machines intelligentes
La prochaine étape des machines intelligentes  Du Neurone Biologique au Neurone Formel: Simplification du Cerveau
Du Neurone Biologique au Neurone Formel: Simplification du Cerveau  Intelligence artificielle: l'explosion du gigantisme
Intelligence artificielle: l'explosion du gigantisme  Quand l'intelligence artificielle devient folle!
Quand l'intelligence artificielle devient folle!  Emergence de l'intelligence artificielle: Illusion d'intelligence ou intelligence?
Emergence de l'intelligence artificielle: Illusion d'intelligence ou intelligence?  Défi et menace de l'Intelligence Artificielle
Défi et menace de l'Intelligence Artificielle  Comment les machines comprennent, interprètent et génèrent un langage de manière similaire à celle des humains?
Comment les machines comprennent, interprètent et génèrent un langage de manière similaire à celle des humains?  Comment fonctionne un réseau de neurones artificiels?
Comment fonctionne un réseau de neurones artificiels?