人工ニューラル ネットワークがどのように機能するかを理解するには、人工知能 (AI) の意味を理解する必要があります。 AI は、人間の介入なしにタスクを自動化できるだけでなく、学習、適応、改善、コミュニケーション、そして何よりも意思決定を行うことができるコンピューター システムを作成することで構成されます。 この意味で、AI は人間の知性の側面を再現しようとしています。
知性の定義は非常に議論の余地がありますが、ここで私たちが興味を持つ意味は次のとおりです。脳によって制御される機能。 実際、歩行のような機械的なものであっても、意思決定のような認知的なものであっても、機能の構造は私たちの脳のすべての大脳領域で同じままです。 さらに、すべての機能は同等に重要であり、高貴とみなされるものとそうでないものとの区別はありません。 これらはすべて、情報を交換するために相互接続された数十億のニューロンの巨大なネットワークを通じて、同じ複雑さの計算で実行されます。 情報は電気信号および化学信号を通じて交換されます。
人間の脳では、ニューロン間の通信プロセスは次のとおりです。
- ニューロンの細胞膜で開始された電気信号が臨界閾値に達すると、「活動電位」と呼ばれる短い電気インパルスが引き起こされます。 活動電位は軸索に沿ってニューロンのシナプスまで移動します。
- シナプス (ニューロン間の接触点) のレベルでは、活動電位が「神経伝達物質」と呼ばれる化学分子の放出を引き起こします。
- 神経伝達物質は、シナプス後ニューロンの膜上にある受容体 (受容体ニューロン) に結合します。 この化学結合は、シナプス後ニューロンで電気応答を引き起こします。
- シナプス後ニューロンは、送信ニューロンから受け取ったすべての入力を統合し、臨界閾値に達すると、今度は活動電位を生成し、それが自身の軸索に沿って伝播し、ネットワーク内の情報の伝達を継続します。
放出される神経伝達物質の種類に応じて、シナプス前活動はシナプス後ニューロンの電気活動に興奮性または抑制性の影響を与える可能性があります。 これにより、活動電位の発火が多かれ少なかれ起こりやすくなります。
この複雑なプロセスは、脳の機能と人間の認知の基礎です。 研究者らはこのプロセスから人工知能モデルを開発します。最初は非常に単純ですが、技術の進歩が進むにつれてますます洗練されます。
ザ人工ニューロン人工ニューラル ネットワークの基本単位です。 人工ニューラル ネットワークは、相互接続されたニューロンの一連の層で構成されており、各層は前の層の出力から入力を取得します。
人工ニューロンはコンピューターのビット (0 または 1) ではなく、数学的な抽象概念 (数値、演算、関数、方程式、行列、集合、確率など) です。 言い換えれば、これらは、提供されたデータに対して数学的演算を実行する処理ユニットです。 コンピュータービットはデジタル情報を保存するための基礎ですが、データは保存されません。
人工ニューラル ネットワークでは、各ニューロンは、「」と呼ばれる変数によって捉えられる活動レベルによって特徴付けられます。活性化電位」。 ニューロンのシナプスは、「」と呼ばれる別の変数によって特徴付けられます。シナプス重量」。
- 活性化電位は、特定の瞬間におけるシナプス後ニューロンの電気的状態を表します。 これは、シナプス前ニューロンからの入力信号を合計することによって計算され、各信号は対応するシナプスの重みによって変調されます。 活性化電位は、入力信号の強度に応じて、負の値から正の値までの範囲で連続的に変化します。
- シナプスの重みは、シナプス接続が興奮性であるか、抑制性であるか、または無効であるかを決定します。 重みは、活性化電位に対する入力信号の影響を調整します。 正の重みを指定するとアクティビティが増加し、負の重みを指定するとアクティビティが減少します。重みが 0 の場合は効果がありません。
活性化電位は、シナプス重みによって重み付けされた入力信号の組み合わせから生じます。 この電位には、非線形性が導入され、シナプス後ニューロンが応答 (活動電位) を生成するかどうかが決定される活性化関数が適用されます。 最終的に、これらのメカニズムにより、ニューロンは情報を処理し、適応的に刺激に応答できるようになります。 これらの変数の機能は、生物学的ニューラル ネットワークと人工ニューラル ネットワークの両方において、ニューロンの動作をモデル化するための基本です。
画像分類に使用される人工ニューラル ネットワークを想像してみましょう。 このネットワークには、3 つのシナプス前ニューロンからの接続を受け取るシナプス後ニューロンが含まれています。 これら 3 つのシナプス前ニューロンはそれぞれ、ネットワークが分析する画像の特定の特徴 (たとえば、垂直線、水平線、曲線の存在) に関連付けられています。
シナプス後ニューロンの初期発火電位は 0 です。
3 つのシナプス前ニューロンが信号を送信すると、各信号には、対応する接続に関連付けられたシナプスの重みが乗算されます。 シナプスの重みが次のようになると仮定します。
- 縦線特性のシナプスウェイト: +0.5
- 横線の特徴に対するシナプスウェイト: -0.3
- カーブの特徴に対するシナプスの重み: +0.2
3 つのシナプス前ニューロンからの信号は、それぞれのシナプスの重みによって重み付けされ、合計されます。
次の信号があるとします。
- 縦線用信号:1
- 横線用信号:0.5
- カーブの信号: 0.8
活性化ポテンシャルは次のように計算されます。
活性化電位 = (1 * 0.5) + (0.5 * (-0.3)) + (0.8 * 0.2) = 0.5 - 0.15 + 0.16 =0.51
活性化電位が定義された閾値 (例: 0) を超えると、シナプス後ニューロンは活動電位を生成し、画像内で目的の特徴が検出されたことを示します。
この例では、シナプスの重みが各画像特徴の相対的な重要性を決定する上で重要な役割を果たします。 シナプス重みによって重み付けされた入力信号は、活性化電位を計算するために使用されます。活性化電位が閾値を超えると、シナプス後ニューロンの応答がトリガーされます。 これにより、ニューラル ネットワークは画像内で検出された特徴に基づいて決定を下すことができます。
インフラストラクチャーハードウェア人工ニューラル ネットワークには生物学的な要素は何も含まれておらず、古典的なコンピューティング (マイクロプロセッサ、グラフィックス カードなど) のネットワークと同じです。
インフラストラクチャーソフトウェア人工ニューラルネットワークとは異なります。 機械学習アルゴリズムはデータから学習し、提供された例に基づいて動作を調整しますが、従来のプログラミング アルゴリズムは、それ自体では変更されない静的な明示的な命令に基づいています。 この意味で AI は革命です。1,750 億のパラメーターを含む ChatGPT 3.5 のルールを静的に記述するには数千年かかるからです。
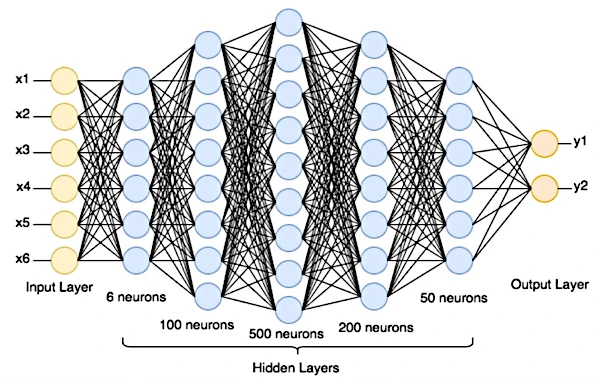
ニューラル ネットワークは、各人工ニューロン (数学関数) が入力を受け取り、これらの入力に対して計算を実行して出力を生成する層で構成されます。 最初の層は入力層で、生データ (テキスト、デジタル画像、またはその他の収集されたデータ) を受け取ります。 その背後には 1 つ以上の隠れ層 (外部からアクセスできない) があり、その後に予測を生成する出力層があります。
予測を行うために、データは入力層から出力層に伝播されます。 各ニューロンは重み付けされた入力を合計し、活性化関数を適用して、結果を次の層に渡します。
活性化関数はネットワークに非線形性を導入します。 これは、量間の関係が一定の割合ではなく、確率であることを意味します。 これにより、ニューラル ネットワークに、画像認識から機械翻訳、自然言語モデリングに至るまで、さまざまな問題を解決する能力が与えられます。
予測を行った後、ネットワークは自身の結果を正しいラベルと比較して、2 つの間の誤差または差異を測定します。 正しいラベルは、教師あり学習モデルのトレーニング セットの重要なコンポーネントです。 これらは、モデルが正確な予測を行うことを学習できるように、トレーニング セット内の各例に提供されます。
次のステップでは、逆伝播アルゴリズムがネットワークの重み (ニューロンが入力にどのように反応するかを決定する内部パラメーター) を調整します。 これにより、モデルの誤差を最小限に抑える値を見つけることができます。 このプロセスは、ネットワークが満足のいくパフォーマンス レベルに達するまで繰り返されます。
ネットワークには、学習率 (トレーニング中に重みを更新するときにモデルが行う反復回数)、使用するバッチ サイズ (重みが更新されるたびに使用されるサンプル データの数)、ネットワーク アーキテクチャ (層の数と層ごとのニューロンの数)、層内の活性化関数の選択など、調整するハイパー パラメーターもあります。
研究者は、各組み合わせのモデルを評価した後、検証データで最高のパフォーマンスを発揮するハイパー パラメーターを選択します。
最終的に、トレーニングされたモデルは、これまでに見たことのない新しいデータに基づいて評価されます。
0 から 9 までの手書きの数字を表すグレースケールの 28x28 ピクセルの 100,000 個の異なる画像を提供できるデータ センターがあると仮定します。
私たちのニューラル ネットワークには、画像のサイズ (28x28 ニューロン) に設定された入力層、1 つ以上の隠れ層、および 10 個のニューロン (0 から 9 までの 10 個の数値があるため) を含む出力層があります。 出力層の各ニューロンは、画像が特定の数字に一致する確率を表します。
ニューロン間の接続の重みは、最初はランダムな値に設定されます。
生データ、たとえば 3 のデジタル画像が入力層に導入されます。
画像の局所領域を分析するには、畳み込みフィルター (例: 5x5 ピクセル) を画像上でピクセルごとにスライドさせて、階層的な視覚的特徴マップを抽出します。 通常、畳み込み層ではいくつかの異なるフィルターが使用されます。 各フィルターは、エッジ、テクスチャ、パターンなどの画像の特定の特徴を検出することを学習します。 最初の畳み込み層によって抽出された特徴は単純なもの (エッジなど) ですが、上位層はより複雑な特徴 (パターンやオブジェクトなど) を認識することを学習します。
データは、重み付けされた接続に従い、アクティベーション関数を適用することによって、ネットワークを介して伝播します。 各層で数学的演算が実行されて出力が得られます。
出力層は、各桁 (0 ~ 9) のスコアを生成します。 関数は、これらのスコアを、考えられる各クラス (0 ~ 9) の一連の確率に変換します。 最も確率の高い数値がネットワークの予測になります。
次に、ネットワークはその予測を画像の実際のラベル (たとえば、「それは 3」) と比較します。
コスト関数は、モデルの予測と実際のラベルの間の乖離を測定します。 モデルの予測が予想されるラベルからかけ離れている場合、より高いコストが割り当てられます。 ニューラル ネットワークをトレーニングするときの目的は、コスト関数を最小限に抑えることです。
これを行うために、エラーはネットワークを通じて逆方向に伝播されます。 この逆伝播は、出力層から入力層に進みます。 誤差が逆方向に伝播すると、ネットワークは各層のパラメータ (重みとバイアス) を調整して誤差を最小限に抑えます。 これは、モデル パラメーターを更新する勾配降下法などの最適化アルゴリズムを使用して行われます。 重みとバイアスは勾配に応じて調整されます。 パラメータはコスト関数を最小化する方向に変更されます。
このプロセスは、非常に多くのトレーニング画像に対して繰り返されます。 ネットワークは反復ごとにパラメータを調整して、手書き数字の分類を改善します。
ネットワークがトレーニングされると、別のデータセット (まだ表示されていない画像) でテストされ、分類精度の観点からそのパフォーマンスが評価されます。
重みを変更するという概念は人間の脳の機能からインスピレーションを得ているため、人工ニューラル ネットワークで使用されます。 人間の脳では、ニューロンはシナプスによって互いに接続されています。 2つのニューロン間の結合の強さは「シナプス重み」と呼ばれます。 シナプスの重みは人間の学習プロセス中に変更されます。 このプロセスはまだ十分に理解されていませんが、シナプス可塑性と呼ばれます。 シナプス可塑性は、私たちが生涯にわたって適応し学習することを可能にする魅力的なプロセスです。
例えば :
• フランス語で「chien」という単語を学習すると、「ch」音、「i」音、「e」音、および「chien」という単語を表すニューロンが一緒に活性化されます。 「犬」という言葉を使えば使うほど、これらのニューロンが一緒に活性化されます。
• トラウマを負った人がポジティブで安全な経験にさらされるほど、トラウマ的な出来事を表すニューロン間のシナプスが弱くなる可能性が高くなります。
 なぜヒマワリは太陽の方を向くのか?ラグランジアンによる解答
なぜヒマワリは太陽の方を向くのか?ラグランジアンによる解答  世界人口2026:大陸別の人口動向
世界人口2026:大陸別の人口動向  なぜ生命は不均衡から生まれ、熱力学的平衡で消滅するのか
なぜ生命は不均衡から生まれ、熱力学的平衡で消滅するのか  電磁スペクトルと視覚:私たちの目が捉える地球の姿
電磁スペクトルと視覚:私たちの目が捉える地球の姿  自己と非自己:物理法則から見たアイデンティティの簡単な解説
自己と非自己:物理法則から見たアイデンティティの簡単な解説  分子時計:突然変異の偶然性から時間の測定へ
分子時計:突然変異の偶然性から時間の測定へ  ホワイトサンズの足跡:アメリカ大陸の最初の一歩
ホワイトサンズの足跡:アメリカ大陸の最初の一歩 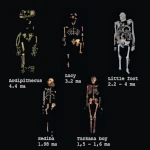 ホミニン:出現、拡散、絶滅
ホミニン:出現、拡散、絶滅 主要な自然災害:最も可能性の高い脅威は何か?
主要な自然災害:最も可能性の高い脅威は何か? 文明の大崩壊:重要な時期と原因
文明の大崩壊:重要な時期と原因 生成AI vs AGI:模倣の終わり、意識の始まりはどこか?
生成AI vs AGI:模倣の終わり、意識の始まりはどこか?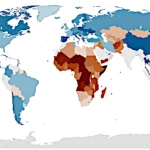 出生率の低下:人口災害か自然な進化か?
出生率の低下:人口災害か自然な進化か? 自然選択 vs 偶然:なぜ進化は宝くじではないのか?
自然選択 vs 偶然:なぜ進化は宝くじではないのか? 生命が地球から始まったら?パンスペルミア理論の革命
生命が地球から始まったら?パンスペルミア理論の革命 世界を激変させる大分岐:生存か崩壊か?
世界を激変させる大分岐:生存か崩壊か? 原始化学:最初の有機分子はどこで生まれたのか?
原始化学:最初の有機分子はどこで生まれたのか? COとCO₂:2つのガス、2つのリスク、2つの生物学的メカニズム
COとCO₂:2つのガス、2つのリスク、2つの生物学的メカニズム 自発的同期:物理学から生命までの普遍的現象
自発的同期:物理学から生命までの普遍的現象 人工ネットワーク vs 生物学的ネットワーク:2つのシステム、共通のアーキテクチャ
人工ネットワーク vs 生物学的ネットワーク:2つのシステム、共通のアーキテクチャ 人間の脳と人工知能:類似点と相違点
人間の脳と人工知能:類似点と相違点 時間的課題:10億年をどのように視覚化するか?
時間的課題:10億年をどのように視覚化するか? 生命の誕生に不可欠な3つの要素
生命の誕生に不可欠な3つの要素 なぜホモ属は90万年前に絶滅の危機に瀕したのか?
なぜホモ属は90万年前に絶滅の危機に瀕したのか? AlphaGo vs AlphaGo Zero:人工知能の革命
AlphaGo vs AlphaGo Zero:人工知能の革命 知的機械の次のステップ
知的機械の次のステップ 生命誕生への第一歩
生命誕生への第一歩 生物学的ニューロンから形式ニューロンへ:脳の単純化
生物学的ニューロンから形式ニューロンへ:脳の単純化 影の生物圏
影の生物圏 人間中心主義の衰退
人間中心主義の衰退 人工知能:巨大化の爆発
人工知能:巨大化の爆発 人工知能が狂ったとき!
人工知能が狂ったとき! 人工知能の誕生:知能の幻想か、本当の知能か?
人工知能の誕生:知能の幻想か、本当の知能か? カブトガニ:生きている化石!
カブトガニ:生きている化石! 宇宙における生命の存在:バイオシグネチャー
宇宙における生命の存在:バイオシグネチャー 人工知能の課題と脅威
人工知能の課題と脅威 機械は人間と同様に言語を理解し、解釈し、生成する方法
機械は人間と同様に言語を理解し、解釈し、生成する方法 人工ニューラルネットワークの仕組み
人工ニューラルネットワークの仕組み 生命の起源:パンスペルミア理論
生命の起源:パンスペルミア理論 生命の起源:ホワイトスモーカー理論
生命の起源:ホワイトスモーカー理論 なぜ37度セルシウスなのか?
なぜ37度セルシウスなのか? 私たちは宇宙で孤独なのか?科学と推測の間で
私たちは宇宙で孤独なのか?科学と推測の間で 氷の中の生命の痕跡:先史時代のマムートの出現
氷の中の生命の痕跡:先史時代のマムートの出現 ドリアス期:メガファウナを絶滅させたミニ氷河期
ドリアス期:メガファウナを絶滅させたミニ氷河期 2つの大氷河期:凍った地球の海で生き残る
2つの大氷河期:凍った地球の海で生き残る 動物の切断後の再生:器官の再生
動物の切断後の再生:器官の再生 生命の果て:地底のメフィスト、深淵の虫
生命の果て:地底のメフィスト、深淵の虫 宇宙で固体フラーレンが発見される
宇宙で固体フラーレンが発見される 人間の歩行:原人の二足歩行の起源
人間の歩行:原人の二足歩行の起源 カラボ:人間進化の窓
カラボ:人間進化の窓 過ぎ去る時間
過ぎ去る時間 無生物から生命への移行
無生物から生命への移行 複雑さの物語:素粒子から最初の生物まで
複雑さの物語:素粒子から最初の生物まで メガポード:火山の熱を利用する
メガポード:火山の熱を利用する アルディピテクス:440万年前のエチオピアの原人
アルディピテクス:440万年前のエチオピアの原人 自然選択:カバマダラの例
自然選択:カバマダラの例 オルドビス紀:サンゴ、三葉虫、放散虫の時代
オルドビス紀:サンゴ、三葉虫、放散虫の時代 液体の水:単なる溶媒以上、化学反応の促進剤
液体の水:単なる溶媒以上、化学反応の促進剤 ネアンデルタール人:人類の失われたいとこ
ネアンデルタール人:人類の失われたいとこ アシモ:未来のヒューマノイド
アシモ:未来のヒューマノイド 生命の誕生を可能にした条件は何か?
生命の誕生を可能にした条件は何か? フェルミのパラドックスとプラトンの洞窟:私たちは孤独か、それとも盲目か?
フェルミのパラドックスとプラトンの洞窟:私たちは孤独か、それとも盲目か? クマムシ:生物学の法則に挑戦する不死身の生物
クマムシ:生物学の法則に挑戦する不死身の生物 トゥーマイ:最古の原人の一つ
トゥーマイ:最古の原人の一つ 生命の樹:数十億の絶滅種と単一の祖先コミュニティ
生命の樹:数十億の絶滅種と単一の祖先コミュニティ 深海の生命:極限の適応を遂げた生物
深海の生命:極限の適応を遂げた生物 シアノバクテリアと酸素危機:原始的な環境災害
シアノバクテリアと酸素危機:原始的な環境災害 物質から生命へ:生物学的出現の曖昧な境界
物質から生命へ:生物学的出現の曖昧な境界 世界最小のカエル:微小脊椎動物の生理的秘密
世界最小のカエル:微小脊椎動物の生理的秘密 小氷期の説明
小氷期の説明 生命の光:月が明かすバイオシグネチャー
生命の光:月が明かすバイオシグネチャー 生きている光:生物発光の驚異的な秘密
生きている光:生物発光の驚異的な秘密 感覚を超えて:科学の大革命
感覚を超えて:科学の大革命 原始のスープ:地球生命の化学的揺籃
原始のスープ:地球生命の化学的揺籃 世界人口:10億人から人口飽和へ
世界人口:10億人から人口飽和へ 生態学と崩壊:イースター島の事例
生態学と崩壊:イースター島の事例 フラクタル:自己組織化された普遍的構造
フラクタル:自己組織化された普遍的構造