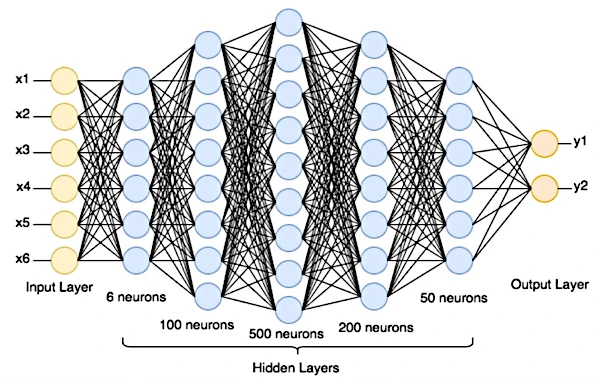
Ein künstliches neuronales Netz ist ein Computersystem, das aus mathematischen Verarbeitungseinheiten (künstliche Neuronen) besteht, die in miteinander verbundenen Schichten organisiert sind. Inspiriert von der Funktionsweise des menschlichen Gehirns lernt es aus Daten, indem es seine „synaptischen Gewichte“ anpasst, um Aufgaben wie Bilderkennung oder Sprachverarbeitung durchzuführen, ohne dass alle Regeln explizit programmiert werden müssen.
Um die Funktionsweise künstlicher neuronaler Netze zu verstehen, ist es notwendig, die Bedeutung von künstlicher Intelligenz (KI) zu begreifen. KI besteht darin, Computersysteme zu schaffen, die in der Lage sind, Aufgaben ohne menschliches Eingreifen zu automatisieren, sowie zu lernen, sich anzupassen, sich zu verbessern, zu kommunizieren und vor allem Entscheidungen zu treffen. In diesem Sinne versucht die KI, Aspekte der menschlichen Intelligenz nachzubilden.
Die Definition von Intelligenz ist sehr umstritten, aber die Bedeutung, die uns hier interessiert, ist die der vom Gehirn kontrollierten Funktionen. Tatsächlich bleibt die Architektur der Funktionen in allen Bereichen unseres Gehirns gleich, ob es sich um mechanische Funktionen wie Gehen oder kognitive Funktionen wie Entscheidungsfindung handelt. Außerdem sind alle Funktionen von gleicher Bedeutung, ohne Unterscheidung zwischen denen, die als edel oder weniger edel angesehen werden. Sie werden alle mit der gleichen Komplexität von Berechnungen durchgeführt, durch ein riesiges Netzwerk von Milliarden von Neuronen, die miteinander verbunden sind, um Informationen auszutauschen. Informationen werden durch elektrische und chemische Signale ausgetauscht.
Im menschlichen Gehirn ist der Kommunikationsprozess zwischen Neuronen wie folgt:
- Wenn elektrische Signale, die an der Zellmembran des Neurons ausgelöst werden, eine kritische Schwelle erreichen, lösen sie einen kurzen elektrischen Impuls aus, der als "Aktionspotenzial" bezeichnet wird. Aktionspotenziale wandern entlang des Axons zur Synapse des Neurons.
- An der Synapse (Kontaktpunkte zwischen den Neuronen) lösen die Aktionspotenziale die Freisetzung chemischer Moleküle aus, die als "Neurotransmitter" bezeichnet werden.
- Die Neurotransmitter binden sich dann an die Rezeptoren, die sich auf der Membran des postsynaptischen Neurons (des empfangenden Neurons) befinden. Diese chemische Bindung löst eine elektrische Reaktion im postsynaptischen Neuron aus.
- Das postsynaptische Neuron integriert alle Eingaben, die es von den sendenden Neuronen erhält, und wenn die kritische Schwelle erreicht wird, erzeugt es seinerseits ein Aktionspotenzial, das sich entlang seines eigenen Axons ausbreitet und so die Übertragung von Informationen im Netzwerk fortsetzt.
Je nach Art der freigesetzten Neurotransmitter kann die präsynaptische Aktivität eine erregende oder hemmende Wirkung auf die elektrische Aktivität des postsynaptischen Neurons haben. Dies macht das Auslösen eines Aktionspotenzials mehr oder weniger wahrscheinlich.
Dieser komplexe Prozess ist die Grundlage für die Funktionsweise des Gehirns und der menschlichen Kognition. Ausgehend von diesem Prozess haben Forscher ein Modell für künstliche Intelligenz entwickelt, das zunächst sehr einfach war und im Laufe des technologischen Fortschritts immer ausgefeilter wurde.
Das künstliche Neuron ist die grundlegende Einheit eines künstlichen neuronalen Netzes. Ein künstliches neuronales Netz besteht aus einer Abfolge von Schichten miteinander verbundener Neuronen, wobei jede Schicht ihre Eingaben von den Ausgaben der vorherigen Schicht erhält.
Künstliche Neuronen sind keine Computerbits (0 oder 1), sondern eher mathematische Abstraktionen (Zahlen, Operationen, Funktionen, Gleichungen, Matrizen, Mengen, Wahrscheinlichkeiten usw.). Mit anderen Worten: Es sind Verarbeitungseinheiten, die mathematische Operationen an den ihnen präsentierten Daten durchführen. Sie speichern keine Daten, im Gegensatz zu Computerbits, die die Grundlage der digitalen Informationsspeicherung sind.
In einem künstlichen neuronalen Netz ist jedes Neuron durch ein Aktivitätsniveau gekennzeichnet, das durch eine Variable namens "Aktivierungspotenzial" erfasst wird. Die Synapse des Neurons ist durch eine weitere Variable namens "synaptisches Gewicht" gekennzeichnet.
- Das Aktivierungspotenzial repräsentiert den elektrischen Zustand des postsynaptischen Neurons zu einem bestimmten Zeitpunkt. Es wird berechnet, indem die Eingangssignale der präsynaptischen Neuronen summiert werden, wobei jedes Signal durch das entsprechende synaptische Gewicht modifiziert wird. Das Aktivierungspotenzial kann kontinuierlich in einem Bereich von negativen bis positiven Werten variieren, abhängig von der Intensität der eingehenden Signale.
- Die synaptischen Gewichte bestimmen, ob eine synaptische Verbindung erregend, hemmend oder neutral ist. Die Gewichte modulieren die Wirkung der Eingangssignale auf das Aktivierungspotenzial. Positive Gewichte erhöhen die Aktivität, negative Gewichte verringern sie, und Null-Gewichte haben keine Wirkung.
Das Aktivierungspotenzial ergibt sich aus der Kombination der gewichteten Eingangssignale. Dieses Potenzial wird dann einer Aktivierungsfunktion unterzogen, die eine Nichtlinearität einführt und bestimmt, ob das postsynaptische Neuron eine Reaktion (Aktionspotenzial) auslöst oder nicht. Letztendlich ermöglichen diese Mechanismen dem Neuron, Informationen zu verarbeiten und adaptiv auf Reize zu reagieren. Die Funktionsweise dieser Variablen ist grundlegend für die Modellierung des Verhaltens von Neuronen, sowohl in biologischen als auch in künstlichen neuronalen Netzen.
Stellen Sie sich ein künstliches neuronales Netz zur Bildklassifizierung vor. Dieses Netz hat ein postsynaptisches Neuron, das Verbindungen von drei präsynaptischen Neuronen erhält. Jedes dieser drei präsynaptischen Neuronen ist mit einem spezifischen Merkmal des Bildes verbunden, das das Netz analysiert, z. B. das Vorhandensein von vertikalen Linien, horizontalen Linien und Kurven.
Das postsynaptische Neuron hat ein Anfangs-Aktivierungspotenzial von 0.
Wenn die drei präsynaptischen Neuronen ihre Signale senden, wird jedes Signal mit dem synaptischen Gewicht multipliziert, das mit der entsprechenden Verbindung verbunden ist. Angenommen, die synaptischen Gewichte sind wie folgt:
- Synaptisches Gewicht für das Merkmal der vertikalen Linien: +0,5
- Synaptisches Gewicht für das Merkmal der horizontalen Linien: -0,3
- Synaptisches Gewicht für das Merkmal der Kurven: +0,2
Die Signale der drei präsynaptischen Neuronen werden mit ihren jeweiligen synaptischen Gewichten gewichtet und summiert.
Wenn wir die folgenden Signale haben:
- Signal für vertikale Linien: 1
- Signal für horizontale Linien: 0,5
- Signal für Kurven: 0,8
Das Aktivierungspotenzial würde wie folgt berechnet:
Aktivierungspotenzial = (1 * 0,5) + (0,5 * (-0,3)) + (0,8 * 0,2) = 0,5 - 0,15 + 0,16 = 0,51
Wenn das Aktivierungspotenzial einen definierten Schwellenwert (z. B. 0) überschreitet, wird das postsynaptische Neuron ein Aktionspotenzial erzeugen, was anzeigt, dass das gesuchte Merkmal im Bild erkannt wurde.
In diesem Beispiel spielen die synaptischen Gewichte eine entscheidende Rolle bei der Bestimmung der relativen Bedeutung jedes Bildmerkmals. Die gewichteten Eingangssignale werden verwendet, um das Aktivierungspotenzial zu berechnen, das, wenn es den Schwellenwert überschreitet, die Reaktion des postsynaptischen Neurons auslöst. Dies ermöglicht es dem neuronalen Netz, Entscheidungen auf der Grundlage der im Bild erkannten Merkmale zu treffen.
Die Hardware-Infrastruktur eines künstlichen neuronalen Netzes hat nichts Biologisches; sie ist dieselbe wie die der klassischen Informatik (Mikroprozessoren, Grafikkarten usw.).
Die Software-Infrastruktur eines künstlichen neuronalen Netzes ist anders. Maschinelle Lernalgorithmen lernen aus Daten und passen ihr Verhalten basierend auf den bereitgestellten Beispielen an, während traditionelle Programmieralgorithmen auf statischen expliziten Anweisungen basieren, die sich nicht von selbst ändern. In diesem Sinne ist KI eine Revolution, denn um die Regeln von ChatGPT 3.5 mit seinen 175 Milliarden Parametern statisch zu schreiben, hätte es Tausende von Jahren gedauert.
Ein neuronales Netz ist in Schichten organisiert, wobei jedes künstliche Neuron (mathematische Funktion) Eingaben erhält, Berechnungen an diesen Eingaben durchführt und eine Ausgabe erzeugt. Die erste Schicht ist die Eingabeschicht, die die Rohdaten (Text, Digitalbild oder andere gesammelte Daten) erhält. Dahinter gibt es eine oder mehrere versteckte Schichten (von außen nicht zugänglich), gefolgt von der Ausgabeschicht, die die Vorhersagen erzeugt.
Um eine Vorhersage zu treffen, werden die Daten von der Eingabeschicht zur Ausgabeschicht weitergeleitet. Jedes Neuron summiert seine gewichteten Eingaben, wendet eine Aktivierungsfunktion an und gibt das Ergebnis an die nächste Schicht weiter.
Aktivierungsfunktionen führen Nichtlinearitäten in das Netz ein. Dies bedeutet, dass das Verhältnis zwischen den Mengen keine konstante Proportion, sondern eine Wahrscheinlichkeit ist. Dies verleiht neuronalen Netzen die Fähigkeit, eine Vielzahl von Problemen zu lösen, von der Bilderkennung bis zur maschinellen Übersetzung, einschließlich der Modellierung natürlicher Sprache.
Nach dem Treffen einer Vorhersage vergleicht das Netz seine eigenen Ergebnisse mit den korrekten Labels, um den Fehler oder die Differenz zwischen beiden zu messen. Die korrekten Labels sind eine wesentliche Komponente des Trainingsdatensatzes für ein Modell des überwachten Lernens. Sie werden für jedes Beispiel im Trainingsdatensatz bereitgestellt, um dem Modell zu ermöglichen, genaue Vorhersagen zu lernen.
Im nächsten Schritt passt der Backpropagationsalgorithmus die Gewichte des Netzes (interne Parameter, die bestimmen, wie Neuronen auf Eingaben reagieren) an. Dies ermöglicht es ihm, die Werte zu finden, die den Fehler des Modells minimieren. Dieser Prozess wird wiederholt, bis das Netz ein zufriedenstellendes Leistungsniveau erreicht.
Im Netz gibt es auch Hyperparameter, die angepasst werden müssen, wie die Lernrate, die verwendete Batch-Größe, die Netzarchitektur, die Wahl der Aktivierungsfunktion in den Schichten usw.
Nach der Bewertung des Modells für jede Kombination wählen die Forscher die Hyperparameter aus, die die beste Leistung auf den Validierungsdaten liefern.
Letztendlich wird das trainierte Modell mit neuen, bisher nicht gesehenen Daten bewertet.
Angenommen, wir haben ein Rechenzentrum, das uns 100.000 verschiedene 28x28-Pixel-Graustufenbilder zur Verfügung stellen kann, die handschriftliche Ziffern von 0 bis 9 darstellen.
Unser neuronales Netz wird eine Eingabeschicht haben, die auf die Größe der Bilder konfiguriert ist (28x28 Neuronen), eine oder mehrere versteckte Schichten und eine Ausgabeschicht mit 10 Neuronen (da es 10 mögliche Ziffern gibt: 0 bis 9). Jedes Neuron in der Ausgabeschicht repräsentiert die Wahrscheinlichkeit, dass das Bild einer bestimmten Ziffer entspricht.
Die Gewichte der Verbindungen zwischen den Neuronen werden zunächst auf zufällige Werte gesetzt.
Die Rohdaten, z. B. das digitale Bild der Ziffer 3, werden in die Eingabeschicht eingeführt.
Um lokale Bereiche des Bildes zu analysieren, gleiten Faltungsfilter über das Bild, um eine Karte hierarchischer visueller Merkmale zu extrahieren. Die ersten Schichten erkennen Kanten, während höhere Schichten komplexere Muster erkennen.
Die Daten werden durch das Netz weitergeleitet, indem sie den gewichteten Verbindungen folgen und Aktivierungsfunktionen anwenden. In jeder Schicht werden mathematische Operationen durchgeführt, um eine Ausgabe zu erhalten.
Die Ausgabeschicht erzeugt Punktzahlen für jede Ziffer (0-9). Eine Funktion wandelt diese Punktzahlen in Wahrscheinlichkeiten um. Die Ziffer mit der höchsten Wahrscheinlichkeit wird die Vorhersage des Netzes sein.
Anschließend vergleicht das Netz seine Vorhersage mit dem tatsächlichen Label des Bildes.
Eine Kostenfunktion misst die Abweichung zwischen den Vorhersagen des Modells und den tatsächlichen Labels.
Dazu wird der Fehler rückwärts durch das Netz propagiert. Das Netz passt seine Parameter (Gewichte und Biases) in jeder Schicht an, um den Fehler zu minimieren, und zwar mit Algorithmen wie dem Gradientenabstieg.
Dieser Prozess wird über eine sehr große Anzahl von Trainingsbildern wiederholt. Das Netz wird seine Parameter in jeder Iteration anpassen, um die Klassifizierung handschriftlicher Ziffern zu verbessern. Sobald das Netz trainiert ist, wird es mit einem separaten Datensatz getestet, um seine Leistung zu bewerten.
Ein künstliches neuronales Netz ist vom menschlichen Gehirn inspiriert: miteinander verbundene Neuronen tauschen Signale aus, deren Wirkung durch synaptische Gewichte moduliert wird. In seiner künstlichen Version ist jedes Neuron eine mathematische Funktion, die eine gewichtete Summe seiner Eingaben berechnet, eine Aktivierungsfunktion anwendet und das Ergebnis überträgt.
Das Lernen besteht darin, die synaptischen Gewichte automatisch anhand von Beispielen anzupassen, und zwar durch einen Prozess der Rückwärtsausbreitung und Optimierung (Gradientenabstieg). Diese Fähigkeit, ohne explizite Programmierung von Regeln zu lernen, unterscheidet die KI von der klassischen Informatik.
In der Praxis ist das Netz in Schichten organisiert (Eingabe, versteckt, Ausgabe), und nach einem iterativen Training mit gelabelten Daten wird es in der Lage sein, Vorhersagen über neue Daten zu treffen (Bilderkennung, Sprachverarbeitung usw.).
Das biologische Neuron tauscht Informationen über elektrische und chemische Signale (Neurotransmitter) aus. Das künstliche Neuron ist eine mathematische Abstraktion (Zahlen, Funktionen), die Berechnungen durchführt. Im Gegensatz zu Computerbits speichert es keine Daten, sondern verarbeitet Informationen über ein Aktivierungspotenzial und synaptische Gewichte.
Das Lernen erfolgt in drei Hauptschritten: Zuerst trifft das Netz eine Vorhersage, indem es die Eingabedaten durch seine Schichten weiterleitet. Dann vergleicht es seine Vorhersage mit dem korrekten Label über eine Kostenfunktion. Schließlich passt ein Backpropagationsalgorithmus die synaptischen Gewichte an, um den Fehler zu minimieren, und wiederholt diesen Prozess über viele Beispiele.
Aktivierungsfunktionen führen Nichtlinearitäten in das Netz ein. Dies bedeutet, dass das Verhältnis zwischen den Mengen keine konstante Proportion, sondern eine Wahrscheinlichkeit ist. Diese Eigenschaft ermöglicht es neuronalen Netzen, komplexe Probleme wie Bilderkennung, maschinelle Übersetzung oder Modellierung natürlicher Sprache zu lösen.
 KI-Tools: Wie wählt man aus?
KI-Tools: Wie wählt man aus? 
 Generative KI vs AGI: Wo endet Nachahmung, wo beginnt Bewusstsein?
Generative KI vs AGI: Wo endet Nachahmung, wo beginnt Bewusstsein?  Künstliche Netzwerke vs. biologische Netzwerke: Zwei Systeme, eine gemeinsame Architektur
Künstliche Netzwerke vs. biologische Netzwerke: Zwei Systeme, eine gemeinsame Architektur  Menschliches Gehirn und künstliche Intelligenzen: Ähnlichkeiten und Unterschiede
Menschliches Gehirn und künstliche Intelligenzen: Ähnlichkeiten und Unterschiede  AlphaGo gegen AlphaGo Zero: Eine Revolution der künstlichen Intelligenz
AlphaGo gegen AlphaGo Zero: Eine Revolution der künstlichen Intelligenz  Der nächste Schritt intelligenter Maschinen
Der nächste Schritt intelligenter Maschinen  Der erste Schritt zur Entstehung des Lebens
Der erste Schritt zur Entstehung des Lebens  Vom biologischen Neuron zum formalen Neuron: Vereinfachung des Gehirns
Vom biologischen Neuron zum formalen Neuron: Vereinfachung des Gehirns  Künstliche Intelligenz: Die Explosion des Gigantismus
Künstliche Intelligenz: Die Explosion des Gigantismus  Wenn künstliche Intelligenz verrückt wird!
Wenn künstliche Intelligenz verrückt wird!  Entstehung der künstlichen Intelligenz: Illusion oder echte Intelligenz?
Entstehung der künstlichen Intelligenz: Illusion oder echte Intelligenz?  Wie Maschinen Sprache ähnlich wie Menschen verstehen, interpretieren und erzeugen
Wie Maschinen Sprache ähnlich wie Menschen verstehen, interpretieren und erzeugen  Wie funktioniert ein künstliches neuronales Netzwerk?
Wie funktioniert ein künstliches neuronales Netzwerk?